

Hello dear reader! Hope you’re good. Did you know Support Vector Regression (SVR) represents one of the most powerful predictive modeling techniques in machine learning?
As an extension of Support Vector Machines (SVM), Support Vector Regression has revolutionized how data scientists approach complex regression problems.
In this comprehensive guide, we’ll explore everything you need to know about SVR in machine learning, from fundamental concepts to advanced implementations.
What is Support Vector Regression?
Support Vector Regression fundamentally differs from traditional regression methods by introducing an epsilon-tolerant band around the prediction line.
Unlike basic linear regression, Support Vector Regression excels at handling non-linear relationships while maintaining robust prediction capabilities, making it a standout choice for complex machine learning projects.
Core Principles of Support Vector Regression
When implementing SVR in machine learning, three fundamental components work together:
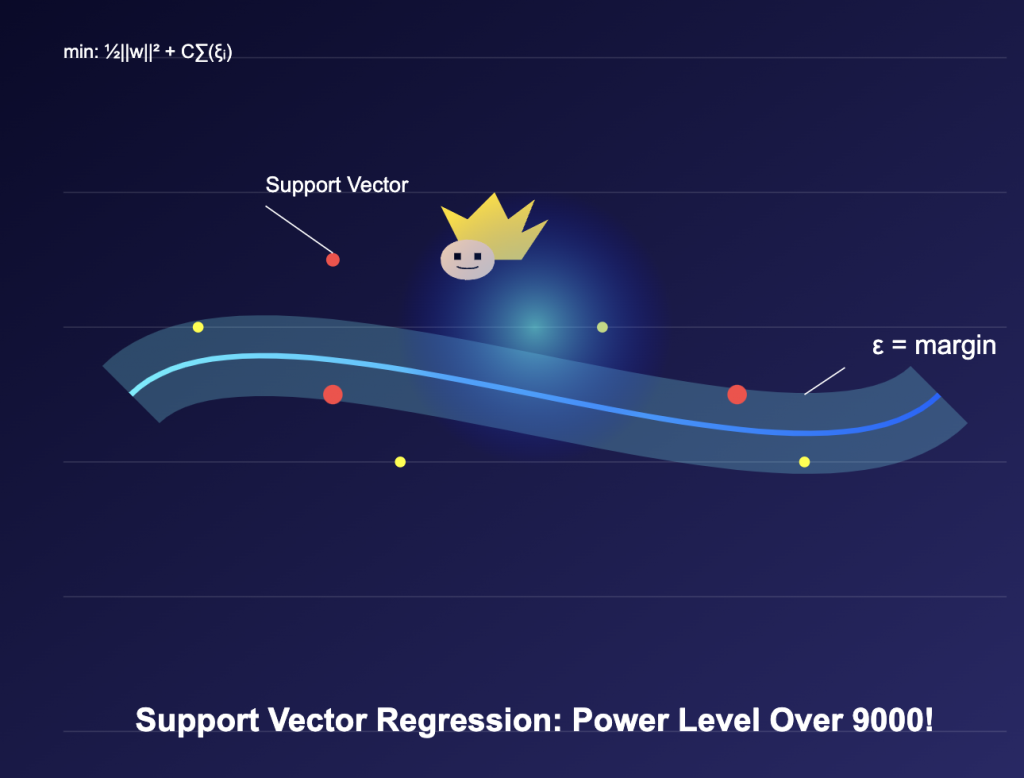
- The Epsilon (ε) Tube:
- Defines the acceptable error margin in Support Vector Regression
- Controls prediction accuracy and model complexity
- Helps optimize the SVR model’s performance
- Support Vectors:
- Key data points that define the regression function
- Determine the boundaries of the ε-tube
- Essential for SVR in machine learning applications
[IMAGE SUGGESTION: Insert technical diagram showing epsilon tube and support vectors with clear labeling]
Mathematical Foundation of Support Vector Regression
The optimization problem underlying SVRs is defined as:
minimize: 1/2 ||w||² + C Σ(ξi + ξi*)
subject to: |yi - (w·xi + b)| ≤ ε + ξiKey components in SVR machine learning models:
- w: Weight vector
- C: Regularization parameter
- ε: Maximum allowed deviation
- ξi, ξi*: Slack variables
Implementing SVR in Machine Learning Projects
Setting Up Your SVR Model
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
# Essential preprocessing for SVR in machine learning
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Initialize Support Vector Regression model
svr_model = SVR(kernel='rbf', C=100, epsilon=0.1, gamma='auto')
# Train the Support Vector Regression model
svr_model.fit(X_scaled, y)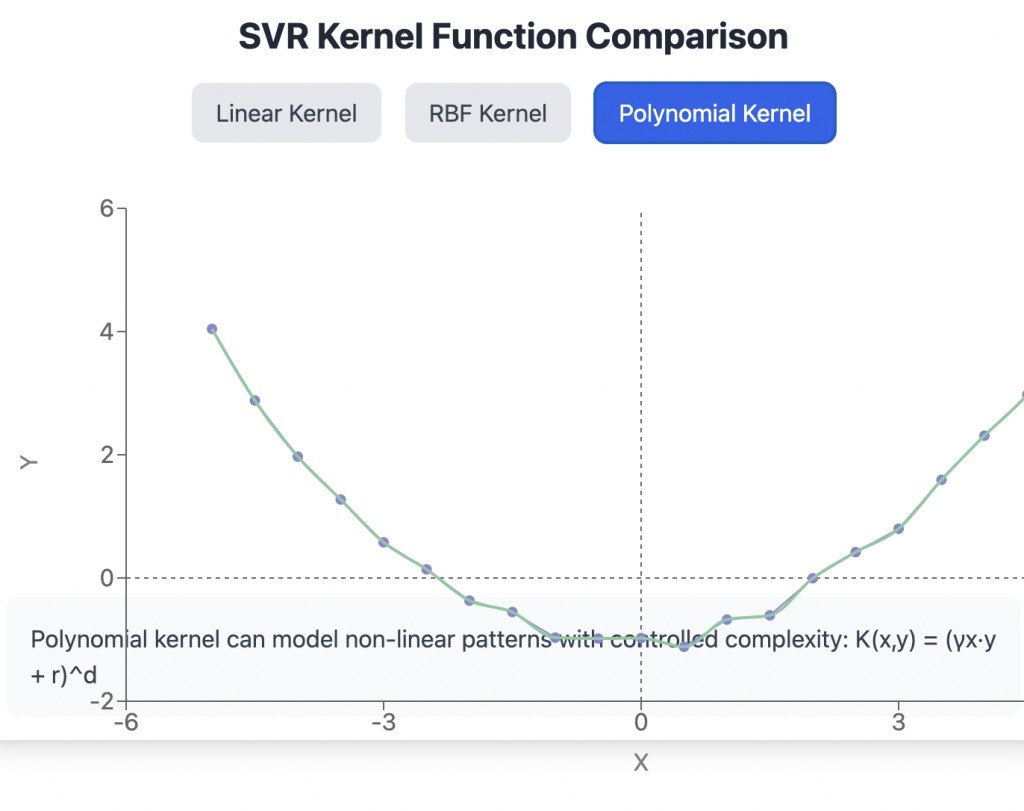
Optimizing SVR Performance
When working with SVR in machine learning, these hyperparameters significantly impact model performance:
- Regularization (C):
- Controls model complexity
- Higher values: Tighter fit to training data
- Lower values: Better generalization
- Epsilon (ε):
- Defines the SVR prediction tolerance
- Affects support vector selection
- Impacts model sparsity
- Kernel Selection: Like SMV’s, they support multiple kernels:
- Linear: For simpler relationships
- RBF: Most commonly used in SVR applications
- Polynomial: For complex nonlinear patterns
Applications of Support Vector Regression
These sort of models have proven effective in various machine learning applications:
- Financial Forecasting:
- Stock price prediction
- Market trend analysis
- Risk assessment
- Environmental Modeling:
- Climate prediction
- Pollution forecasting
- Resource optimization
- Industrial Applications:
- Quality control
- Process optimization
- Demand forecasting
Advanced SVR in Machine Learning
Handling Large-Scale Data
These models are not friend of large datasets, so when applying them to big data consider the following:
- Implement batch processing
- Use online SVR algorithms
- Consider distributed computing solutions
Feature Engineering for SVR
As always, a good ol’ feature engineering can help these models get the maximum juice, so when using them consider:
- Domain-specific transformations
- Polynomial feature expansion
- Feature selection techniques
They do work well when the datasets are kind of rectangular, so wide range of features but not many examples.
Learning Resources
If you want additional support, you can master SVRs with these other AWESOME resources:
- Complete SVR Documentation on scikit-learn
- SVR Mathematical Foundations
- Internal Link: How to Learn Machine Learning
- Practical SVR Implementations
- Our Guide on Online Machine Learning Courses
Summary: Mastering SVR in Machine Learning
These models stand as a cornerstone technique in modern machine learning. Its ability to handle complex nonlinear relationships while maintaining robust predictions makes it invaluable for data scientists and machine learning engineers.
By understanding their fundamentals and mastering its implementation in machine learning projects, you can tackle sophisticated prediction tasks with confidence.
Key takeaways for successful SVR implementation:
- Proper data preprocessing is crucial
- Kernel selection impacts model performance
- Hyperparameter tuning requires systematic approach
- Regular validation ensures model reliability
As always, thank you for reading How to Learn Machine Learning, and have a wonderful day!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
