

A list of the traditional Machine Learning algorithms and models
Looking for a tidy but accesible list of the main Machine Learning algorithms and models? Then read on!
The goal of this post is to outline the most basic, sometimes also called ‘traditional’ Machine Learning models, briefly describe each of them, and guide you to a myriad of resources where you can learn all about them in depth.
We will go from the most simple model to the most complex one, outlining where each model excels, where they can and where they should be used, and see some examples. You can use this post in the future as your go-to guide when debating which ML model to use.
Awesome, now that I have you hooked, lets get to it, starting from the very beginning of the list of machine learning models: Linear Regression.
A Quick List of Machine Learning algorithms and models
Linear Regression
Linear Regression tends to be the Machine Learning algorithm that all teachers explain first, most books start with, and most people end up learning to start their career with.
It is a very simple algorithm that takes a vector of features (the variables or characteristics of our data) as an input, and gives out a numeric, continuous output. As its name and the previous explanation outline, it is a regression algorithm, and the main member and father of the family of linear algorithms where Generalised Linear Models (GLMs) come from.
It can be trained using a closed form solution, or, as it is normally done in the Machine Learning world, using an iterative optimisation algorithm like Gradient Descent.
Linear Regression is a parametric machine learning model (with a fixed number of parameters that depend on the nº of features of our data and that trains quite quickly) that works well for data that is linearly correlated with our target variable (the continuous numeric feature that we want to later predict), that is very intuitive to learn, and easy to explain. It is what we call an ‘explainable AI model’, as the predictions it makes are very easy to explain knowing the model weights.
An example of a Linear Regression model could be a model that predicts house prices taking into account the characteristics of each home like the surface area, location, number of rooms, or if it has an elevator or not.
The following figure shows how Linear Regression would predict the price of a certain house using only 1 feature: The surface area in squared meters of the house. In the case of more variables being included in our model, the X axis would reflect a weighted linear combination of these features.
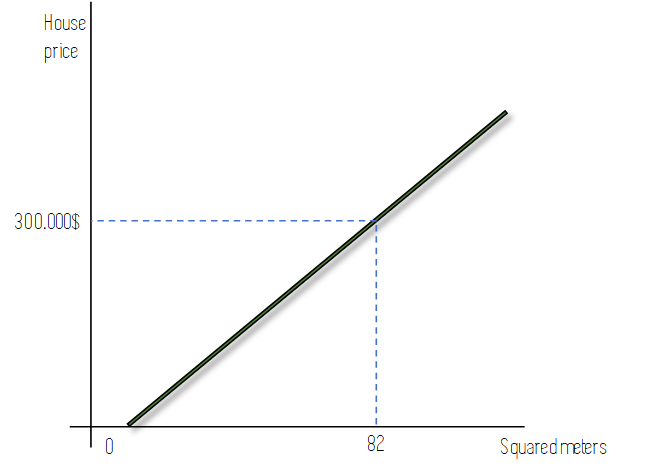
The line from the previous figure would have been fit in the training process using an optimisation algorithm, like gradient descent, that iteratively changes the slope of the line until the best possible line for our task is obtained.
To learn more about it, check out the following resources:
- StatQuest’s Youtube Video: ‘Linear Regression’
- Towards Data Science Article: ‘Linear Regression Explained’
- Machine Learning Mastery: ‘Linear Regression for Machine Learning’
- An Introduction to Statistical Learning: with Applications in R, Chapter 3.
Now that we know what Linear Regression is, lets learn about its discrete brother: Logistic Regression!
Logistic Regression

The second position in our list of Machine learning algorithms is Logistic Regression. Logistic Regression is the brother of Linear Regression that is used for classification instead of regression problems. As linear regression, it takes an input feature vector, but this time it gives out a class label instead of a continuous numeric value.
An example of Logistic Regression could be an algorithm that predicts if a certain patient has a disease or not based on his medical record.
It does this using a sigmoid function, so it not only has the ability to give us the class label (being sick or not), but it can also give us the probability of this event happening; ie, the probability of having a certain disease, or the probability that a customer of our store will buy a certain product.
This is really useful as we can choose to perform different actions depending on the output probability that we get from the model, going further than just the binary prediction.
As Linear regression, it is a very intuitive and explainable algorithm, as by just analysing the model parameters or weights we can see which features of our data are most important, and also see why the model is predicting what it is predicting.
This makes it a very powerful classification model, that is usually the first approach to try when facing a classification problem and looking to get a quick result to establish as a baseline.
The following figure shows an example of a Logistic Regression model that uses only 1 feature (patient weight) to calculate the probability of such patient being obese:
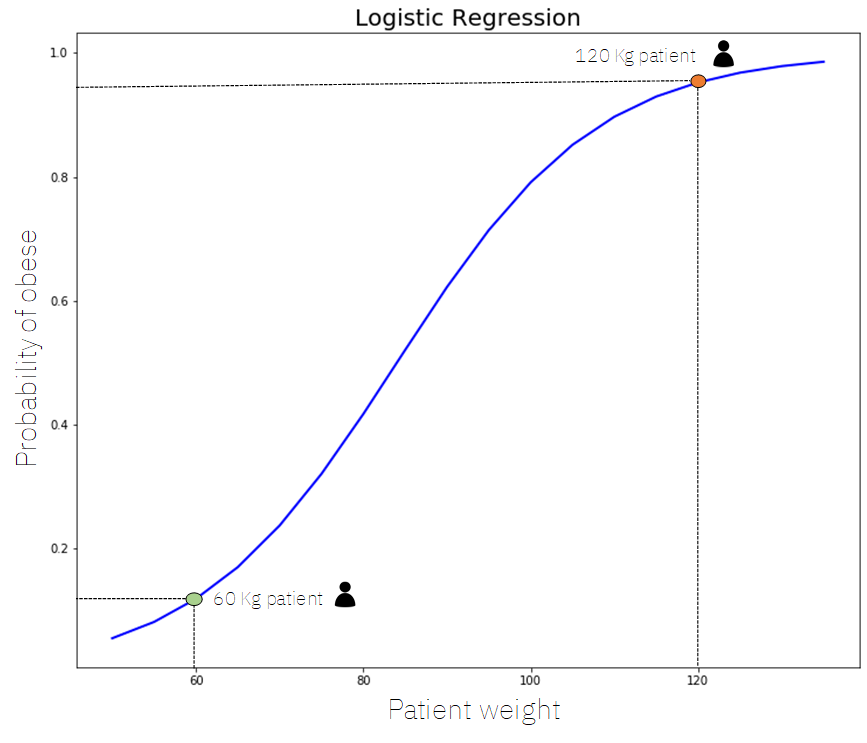
In the previous figure we can see a sigmoid curve with a certain shape used to predict the probability of a 60Kg patient being obese, which as we can see is about 10% (0.1 in the vertical axis) and a 120Kg patient being obese, which as we can see is of about 93% (0.93 in the vertical axis).
If there were more features than just 1, in the horizontal axis we would see a linear weighted combination of these features and in the Y axis we would see the probability again.
For further information on Logistic Regression, check out the following resources:
- StatQuest’s Youtube Video: ‘Logistic Regression’
- Towards Data Science Article: ‘Logistic Regression Explained’
- KD Nuggets: ‘Linear and Logistic Regression Gold Post’ (Awesomely illustrated resource)
- Great concise explanation by Andriy Burkov on ‘The Hundred-Page Machine Learning Book’ Chapter 3.
Oki Doki! Lets carry on to another very simple and intuitive model: A Decision Tree!
Decision Trees
Decision Trees are very versatile Machine Learning models that can be used for both Regression and Classification.
They are constructed using two kinds of elements: nodes and branches. At each node, one of the features of our data is evaluated in order to split the observations in the training process or to make an specific data point follow a certain path when making a prediction.
In a few words, Decision trees are just that: paths where different variables are evaluated that lead to a leave node where similar observations are grouped.
In the training process the tree is built by analysing the possible features along with their values and deciding which features best split our data so that different data points go to one side of the split while minimising some kind of error.
You can see an intuition of what a Decision Tree is in the following figure.
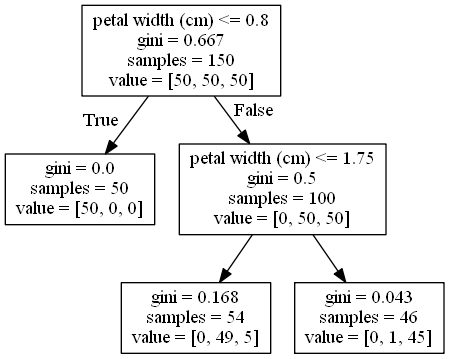
As you can see, they are very simple models, which usually means that they don’t lead to such powerful results as Neural Networks for example, and they also tend to overfit (learn exceptionally well the training set and have a hard time generalising to new data points), which limits their use in the Industry.
However, despite these drawbacks, they are probably the most intuitive and easy Machine Learning model to understand, and by examining which path our data points follow, we can easily know why a tree made a certain prediction.
For classification problems, the selected class when this prediction is made is the most frequent class for the training data points of the leave node where the new observation fell after following its path through the tree. For regression, it is the mean of the target value for such points.
- StatQuest Video: ‘Decision Trees Explained’
- Towards Data Science Article: ‘Decision Trees Explained’
- Towardsai post: ‘Decision Trees Explained with a Practical Example’
- Sebastian’s Raschka explanation on his book ‘Python Machine Learning’, Chapter 3.
Cool! Lets see how to stack numerous Decision Trees to make a Random Forest!
Random Forest

Random Forest models are a kind of nonparametric models that can be used both for regression and classification. They are one of the most popular ensemble methods, belonging to the specific category of Bagging methods.
Ensemble methods involve using many learners to enhance the performance of any single one of them individually. These methods can be described as techniques that use a group of weak learners (those who on average achieve only slightly better results than a random model) together, in order to create a stronger, aggregated one.
In our case, Random Forests are an ensemble of many individual Decision Trees, the family of Machine Learning models we saw just before.
Random Forest introduce randomness and numbers into the equation, fixing many of the problems of individual decision trees, like overfitting and poor prediction power.
In a Random Forest each tree is built using a subset of the training data, and usually only a subset of the possible features. As more and more trees are built, a wider range of our data is used, and more features come into play, making very strong, aggregated models.
Individual trees are built independently, using the same procedure as for a normal decision tree but with only a random portion of the data and only considering a random subset of the features at each node. Aside from this, the training procedure is exactly the same as for an individual Decision Tree, repeated N times.
To make a prediction using a Random Forest each an individual prediction is obtained from each tree. Then, if it is a classification problem, we take the most frequent prediction as the result, and if it is a regression problem we take the average prediction from all the individual trees as the output value. The following figure illustrates how this is done:
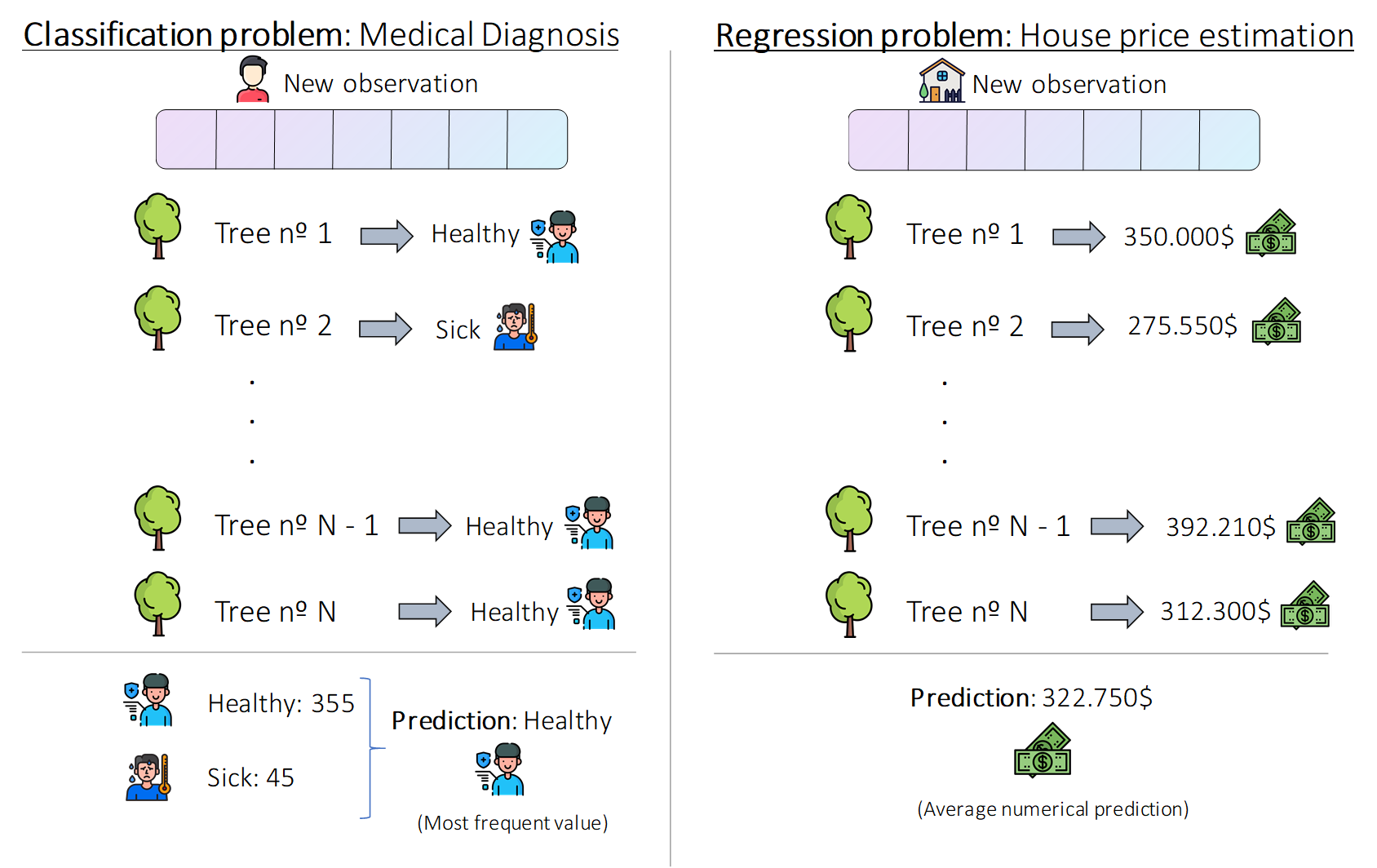
For more information on Random Forest, check out:
- StatQuest’s Video on Random Forest.
- Towards Data Science Post: Random Forest Explained.
- Built In: A complete guide of Random Forest.
Random Forest, along with Boosting methods, are probably the most used of traditional Machine Learning models in industry, because their easy of use, power, and flexibility.
Lets see what these ‘Boosting methods’ are!
Boosting Methods

Boosting methods are similar to the ‘Bagging’ random forest we just saw, but have one key difference: In a Random Forest, all the trees can be built in parallel, they are pretty much independent. In boosting methods, each tree is build sequentially, taking information from the previous tree: Tree 4 depends on what tree 3 is like, tree 3 depends on tree 2, and so on.
Boosting, initially named Hypothesis Boosting, consists on the idea of filtering or weighting the data that is used to train our team of weak learners, so that each new learner gives more weight or is only trained with observations that have been poorly classified by the previous learners.
By doing this our team of models learns to make accurate predictions on all kinds of data, not just on the most common or easy observations. Also, if one of the individual models is very bad at making predictions on some kind of observation, it does not matter, as the other N-1 models will most likely make up for it.
Boosting methods are very powerful, and models from this family like LightGBM, AdaBoost, or XGBoost, along with the previously discussed Random Forests are probably the most used methods when facing ordinary tabular data in the Machine Learning /Data Science Industry.
For more on boosting, check out the following resources:
- What is Boosting in Machine learning? @Towards Data Science
- Boosting by our lovely Udacity.
- Bagging vs Boosting explained on the QuantDare Blog.
Lets finish with the last awesome model: Support Vector Machines!
The last on the list of Machine Learning algorithms: Support Vector Machines

Support vector Machines or SVMs are a widely used family of Machine Learning models, that can solve many ML problems, like linear or non-linear classification, regression, or even outlier detection.
Having said this, their best application comes when applied to the classification of small or medium-sized, complex datasets.
For classification, Support Vector Machines work by creating a decision boundary in between our data, that tries to separate it as best as possible, as shown in the following Figure:
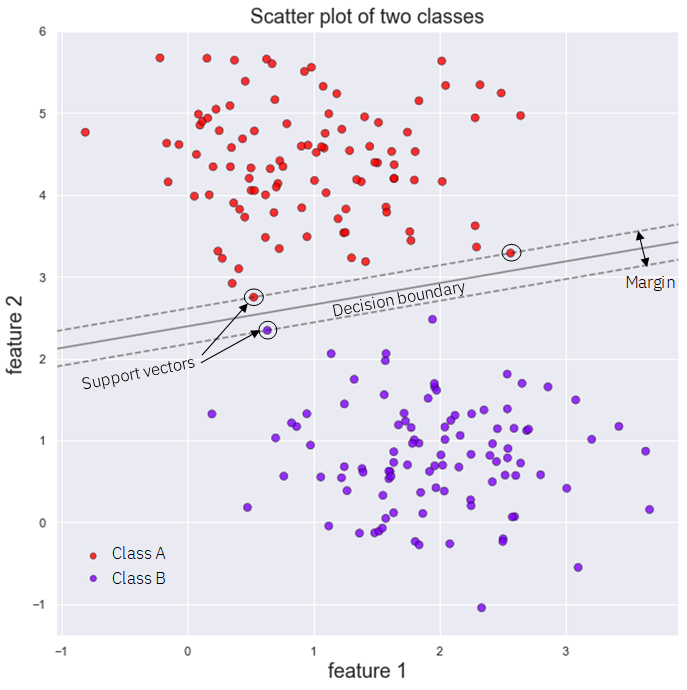
Sometimes, it is imposible to perfectly separate our data using a linear decision boundary, and sometimes it is imposible altogether, so SVMs use a clever trick called the Kernel Trick in order to try to separate our data, although they sometimes have to let a few points of the wrong class be on the side of the Decision boundary where they shouldn’t be.
By tuning how many points, and which kind of kernel we use, SVMs can be very powerful, specially when our data has a lot of features. They take quite a long time to train however, so they should only be used on small or medium sized datasets.
For more resources on SVMS check out:
- Support Vector Machines explained on Towards Data Science.
- SVMs Video by our friend Josh Starmer.
- An Introduction to SVMs on MonkeyLearn.
Closing words and other resources to complement this list of Machine Learning algorithms
That is it! As always, we hope you enjoyed the post, that we managed to help you learn a little bit about the basic Machine Learning algorithms, and given you the resources to go deeper into them.
We have kept out Artificial Neural Networks, and included Boosting models (which some people keep out of this list). Also probabilistic methods have not been included, but we will post some extensive content about them soon. Lastly, unsupervised models have not been included.
To make this article even more complete, we will provide you in the following list with resources to help you decide which Machine Learning algorithm to use in each situation:
- Machine Learning Model Cheat-Sheet for Scikit-Learn.
- Machine Learning algorithms are your friends.
- SaS Machine Learning algorithms Cheat-Sheet.
Also, you can check out our repository of books for more resources on Machine Learning and AI!
For further tutorials on the models covered in this list of machine learning algorithms, check out our Tutorials category. Also if you are looking for great books to go much deeper in this list of machine learning algorithms, check out the following ones:
Book reviews:
- The 100 page Machine Learning Book
- Hands-On Machine Learning with Scikit-Learn & Tensorflow.
- Deep Learning with Python by Francois Chollet.
Have a great day, and don’t forget to follow us on Twitter!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
