

What is Feature Scaling in Machine Learning and why you should consider doing it!
One of the most common data pre-processing methods before we feed our data to our Machine Learning models is Feature Scaling. In this article we will explain what feature scaling is, and why you should consider it as a step on your Data Science pipelines.
What is feature scaling in Machine Learning?
In simple terms, feature scaling consists in putting all of the features of our data (the dependent variables) within the same ranges. It is specially relevant when our Machine learning models use optimisation algorithms or metrics that depend on some kind of Distance Metric.
Lets see a quick example of how feature scaling would work: Imagine we have a dataset with the weights and heights of different people:
- For the heights we use meters, which go from 1.51m in the shortest person to 1.97m in the tallest.
- For the weights we use kilograms which go from 48kg in the lightest to 110kg in the heaviest.
As you can see, in absolute values the range of the weights feature is a lot bigger than the range of the meters feature. One possible solution could be to convert the units of the meters to centimetres, but that would just solve this specific scenarios, and in many cases we have more than two features and cant do this for our whole data set.
Why is feature scaling important?
The following image highlights very quickly the importance of feature scaling using the previous height and weight example:
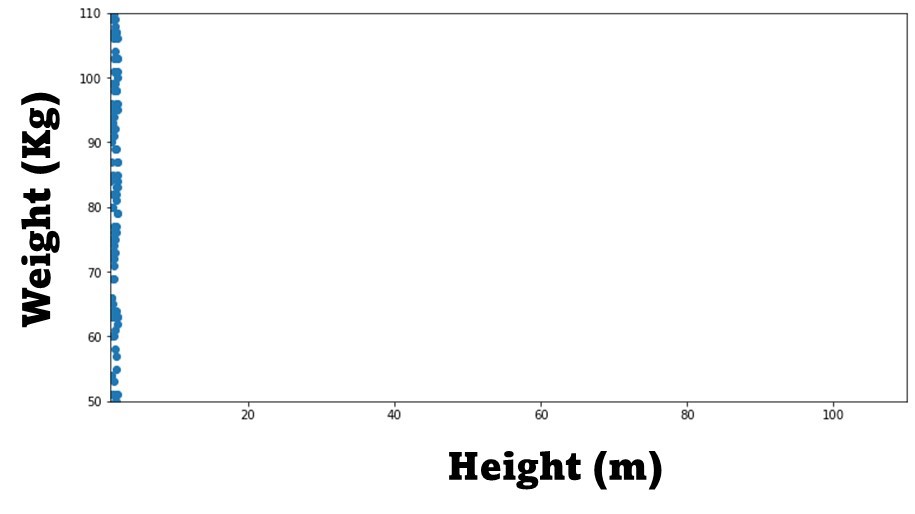
In it we can see that the weight feature dominates this two variable data set as the most variation of our data happens within it. In our X axis the height variable barely has any variability compared to the weight variable in the Y axis.
Because of this, any time we use a Machine learning algorithm that uses some sort of distance metric, the weight variable will have much more impact than the height variable.
If we scale these features using a Minmaxscaler scaling technique (feature scaling in Python, which we will see later how to implement) our weight no longer dominates the feature space, as seen in the following figure:
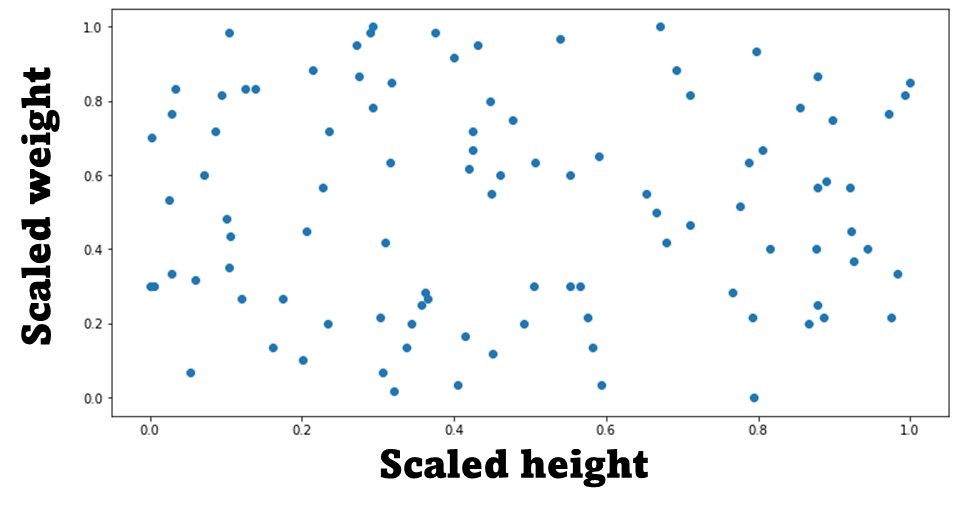
Our Minmaxscaler has put both features in the 0 to 1 range, allowing both of them to have the same order of magnitude and eliminating the dominance of the weight variable we had before.
No products found.
Where Feature Scaling in Machine Learning is applied
As many algorithms like KNN, K-means, etc… use distance metrics to function, any difference in the order of magnitude in the values of our different features will cause the features with the broadest range to dominate the metric, thus taking most of the importance of the model.
Because of this, previous to training any sort of algorithm of this kind, we should apply feature scaling techniques in order to have our variables within the same range.
Lets see the different models and algorithms where feature scaling in machine learning is applied most times:
- The K-Nearest neighbours (KNN) classification algorithm normally uses an euclidean distance metric that will perform much better if some sort of feature scaling is applied to the data.
- In a K-means clusterization algorithm feature scaling is a must as well for the same reason.
- In a Principal Component Analysis (PCA) as we compute the variance under the same unit of measure, feature scaling is essential. Some PCA implementations like Scikit-learn’s performs normalization for you, but it is always good to do it before hand just in case. If you don’t know what Scikit-Learn is, you can learn all about it with our article: What is Scikit-learn?
- Any algorithm that learns using Gradient descent like linear or logistic regression, or artificial neural networks, benefit a lot from some sort of feature scaling both in the speed and the quality of the training, however, it is not 100% mandatory to do it like in the previous 3 cases.
- Algorithms like Decision Trees, Random Forest or Boosting models don’t really care much about the scale of the features, nor do algorithms like Naive Bayes.
It is important to know that like any other sort of data pre-processing technique, the scaling algorithms should be fit on JUST THE TRAINING DATA, and not the whole data set. Also, always consider what sort of data you have before using a feature scaling technique.
Feature scaling techniques: pros and cons
The main feature scaling techniques that are normally use are standarization and normalization:
- Normalization scales our features to a predefined range (normally the 0–1 range), independently of the statistical distribution they follow. It does this using the minimum and maximum values of each feature in our data set, which makes it a bit sensitive to outliers.
- Standardization takes our data and makes it follow a Normal distribution, usually of mean 0 and standard deviation 1. It is best to use it when we know our data follows an standard distribution or if we know there are many outliers.
There is no silver bullet to know when we should apply each one, as it is highly dependent on our data and models, however, as a general rule of thumb you can follow the next guidelines:
- Unsupervised Learning algorithms usually benefit more from standarization than normalization.
- If your variables follow a normal distribution, then standarization works better.
- If the data presents outliers, then standarization is definitely better, as normalization can get hijacked by the existence of extremely low or high values in our features
- In all the other cases normalization is preferable.
Despite these rules though, if you have time we suggest you try both techniques on your data pre-processing pipeline, as as we mentioned earlier the results will vary greatly depending on your data and algorithms.
No products found.
Conclusion and further resources
That is all, we hope you have learned something from this quick feature scaling article. In posterior posts we will explain how to do feature scaling in Python, and include code snippets and charts as well.
We have seen a very simple feature scaling in machine learning example, and in the future post we will continue with a more difficult exercise. Until then, we will leave you with the following great resources to keep learning Machine Learning:
- Our Machine Learning tutorials category
- The best probability and statistic courses online
- A repository with reviews of the most famous Machine Learning books
- Machine learning Data sets to train your own models!
Tags: Feature scaling in machine learning, feature scaling in python, feature scaling in machine learning example, Minmaxscaler.
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
