

Learn what Scikit-Learn, the most famous Python Machine Learning Library is!
Scikit Learn or Sklearn is one of the most used Python libraries for Data Science, along with others like Numpy, Pandas, Tensorflow, or Keras. It is an Open-Source library for Machine Learning in Python, that is actually built on top of three core Python Data Science libraries: Numpy, Scipy and Matplotlib.
In this post we will see what it is, why you should use it, and how you can start mastering it to speed up and enhance your Machine Learning projects. Lets get to it!
What is Scikit Learn?
Scikit–learn is probably the most useful and widely known Machine Learning library for the Python Programming Language.
Sklearn, as it is also known, contains a lot of great tools for machine learning and statistical modelling including classification, regression, clustering and dimensionality reduction. We will see the different elements it contains later in this post.
Basically, it is a software library that allows us to use many pre-made, out of the box Machine Learning models like Linear or Logistic Regression, Decision Trees, Support Vector Machines and a lot more.
What is Scikit Learn used for?
As mentioned earlier, this awesome library is mainly used for training and using Machine Learning models out of the box. It allows developers to not have to build the models from scratch, but rather, take a model that is already built and use it without a worry.
Despite being very easy to use, programmers have to make sure they know the core concepts of the library like transformers and estimators, or what the parameters of our Machine Learning models and pre-processing algorithms are.
At the end of this article we will give a series of very useful tips and tricks that will surely improve your understanding and interaction with the library.
Why should I use Scikit-Learn?
The idea behind this kind of libraries is very easy:
Why reinvent the wheel?
Imagine if every time you wanted to build a Machine Learning model you had to program it from scratch. Development and implementation times would be brutally long, making the field only accesible to those with great knowledge and expertise.
Scikit Learn allows users without a deep knowledge of Machine Learning to use state of the art models, and easily configure the hyper-parameters and train them.
While it might be cool to build and train your models from scratch, in practical terms this is not very escalable, and would drastically improve how long it takes to build, try, and iterate through a Machine Learning pipeline. Also, it would limit the implementation to only those people with a very thorough understanding of both the theoretical and practical part of the models.
What does Scikit-Learn include?
While other libraries like Pytorch, Tensorflow, or Keras focus on Artificial Neural Networks, Scikit-Learn has a more general approach, including the most traditional ML models, rather than ANNs.
The library comes loaded with a lot of features like the following:
- Supervised learning algorithms: The ones we’ve mentioned before – Linear Regression, Logistic, Decision Trees, Random Forest, Support Vector Machines, KNNs, and also some boosting models.
- Cross-validation and Metrics: Cross-Validation and K-folds comes easy with Scikit-Learn, as well as many metrics both for classification and regression algorithms.
- Unsupervised learning algorithms: All the clustering algorithms you can think of, like K-means, hierarchical clustering algorithms and density based like DBScan, as well as dimensionality reduction techniques like Principal Component Analysis or TSne.
- Various toy datasets: Sklearn comes with some pre-defined data sets that you can use out of the box to start learning and solving your first machine learning problems, trying out new techniques, etc…
- Feature extraction: Scikit-learn for extracting features from images and text for example using bag of words, or allows for feature scaling techniques like Max-Min scaling or Standarization.
No products found.
How to use Scikit-Learn
Very easy, you just import the library like so:
from sklearn import svm
and boom, you can start using Support Vector Machines in Python. Just kidding. You first have to install the library, and then you can import it and start building with it.
The goal of this post is not to deeply explain how to use Scikit Learn. Here you can find a quick, get started guide to get you up and running with the library.
Also, if you want to go deeper, we recommend the book No products found.. You can find a full review of the text here.
Tips and Tricks
Despite being a very easy to use library, there are a couple of tips and tricks to make the most out of it. Lets see some of them:
- Get confortable with
fit( )– the main method of the Scikit Learn library. This method is used to get a Scikit Learn object to learn a certain characteristic from data. You should only use this method on training data, and master the Train – Test split, one of the core concepts of Machine Learning that is easily implemented in Scikit Learn. - Understand the difference between estimators and transformers: There are two main kind of objects in Scikit-Learn – estimators and transformers. Both estimators and transformers have the
fit( )method we mentioned before, however only estimators have thepredict( )method. Transformers, as their name suggest, only transform data, while estimators make predictions from this data. - Using Pipelines: Scikit-learn pipelines are a sequence of Machine learning procedures grouped into a single object. For example, we could define a pre-processing step like an Standarization, a PCA and then training a model on the standarised and reduced data. Later, we could use this same pipeline to apply the preprocessing steps to new data and make predictions with the trained model. You can find a good guide on how to use Pipelines here.
- Have a Cheat-sheet near: The library has a pretty neat Cheat sheet that can easily take you to the optimal model to apply to some sort of data. Although this is not always a one fit, it does give some pretty good guidelines. The cheat sheet is the following:
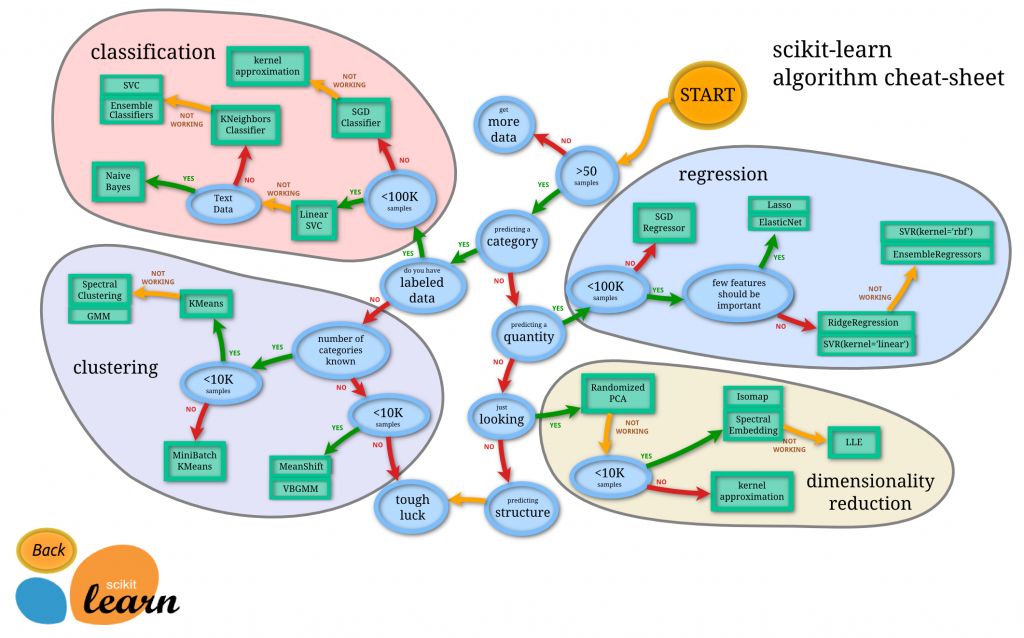
This sheet is great as a first step to know which models to use and where to go.
Summary
That is all, we hope that you liked the post and that you have learned what Scikit learn is: one of the most powerful and at the same time easy to use Python Machine learning libraries out there.
Have a great day and don’t forget to share our site with your friends and follow us on Twitter!
For more information and guides on Machine Learning check out our tutorials category.
Also, for other awesome books and courses about Python and Machine Learning, check out our reviews:
Book reviews:
- The 100 page Machine Learning Book
- Hands-On Machine Learning with Scikit-Learn & Tensorflow.
- Deep Learning with Python by Francois Chollet.
Courses
- Coursera: Machine Learning by Andrew Ng
- Complexity Explorer: Fundamentals of Machine Learning
- Udemy: Python for Data Science and Machine Learning Bootcamp.
Stay tuned, keep learning, and don’t forget to check out our awesome Machine Learning videos!
Tags: Scikit-Learn, Machine Learning, Python programming, Open-Source
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
