
Minmaxscaler Skealearn: how to Normalise your data using Python’s favourite Machine Learning library: Scikit-Learn
Minmaxscaler is the Python object from the Scikit-learn library that is used for normalising our data. You can learn what Scikit-Learn is here.
Normalisation is a feature scaling technique that puts our variable values inside a defined range (like 0-1) so that they all have the same range.
You can learn all about Feature Scaling in Machine Learning with the article linked here, but in short it consists on making the features of our data all have similar value ranges, which is of great importance for any kind of algorithm that uses a distance metric like K-Nearest Neighbours (KNN), K-means clustering, and many others.
In this short snippet we will show you the code needed to do this, explaining every step and parameter involved in detail.
First we need to start with the import, like shown in the following block of code
from sklearn.preprocessing import MinMaxScalerFrom the preprocessing tools in Sklearn we will import MinMaxScaler
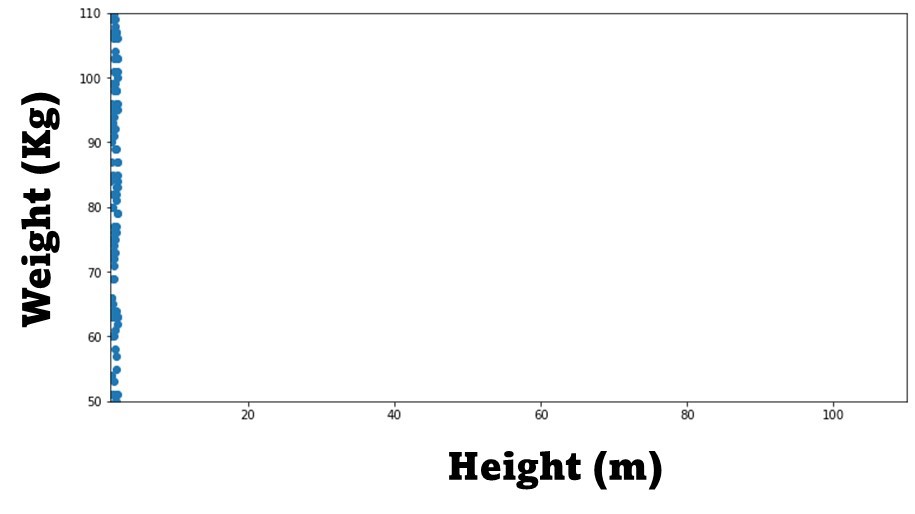
Now, we need some data. For our example we will use a data set that has two features: one is weight in Kg and one is height in meters. The following figure shows that these features variate over very different ranges:
The data points in our vector look like the following, where the first column depicts the height and the second one the weight
data vector = [[1.76, 58],
[1.96, 101],
[1.31, 66],
[1.64, 98],
[1.57, 91],
[1.29, 63],
[2.09, 51]
.
.
.
[1.74, 67]]
To scale the data first we need to create a MinMaxScaler Python object, like shown in the 1st line of code of the following block, and after that we have to train it using our data, which we do in the second line.
scaler = MinMaxScaler()
scaler.fit(data_vector)By doing this we will get the MinmaxScaler Python object to learn the characteristics of our data and its ranges, so that it can later transform all of it to the required scale. In other words, the fit( ) method computes the minimum and maximum of our data to be used for later scaling.
Note that in the previous block we are giving the MinmaxScaler Python object a vector as an input, but we could have given it a pandas Datafrrame too, like shown in the following block:
dfTest = pd.DataFrame({'A':[14.00,90.20,90.95,96.27,91.21],
'B':[103.02,107.26,110.35,114.23,114.68]})
scaler.fit(dfTest[['A', 'B']])Once the MinMaxScaler object is trained, we can use it to scale our data using the transform( ) method:
scaled_data = scaler.transform(data_vector)Which will give us an scaled output array if we used an array, like in the following block showing scaled_data, which is the scaled version of our data_vector:
[[0.58494374, 0.13333333],
[0.78692067, 0.85 ],
[0.11648075, 0.26666667],
[0.46067416, 0.8 ],
.
.
.
.
[0.38813854, 0.68333333]]This could have also been done for Dataframe columns like so:
dfTest[['A', 'B']] = scaler.transform(dfTest[['A', 'B']])Awesome, lets see how our data looks like now!
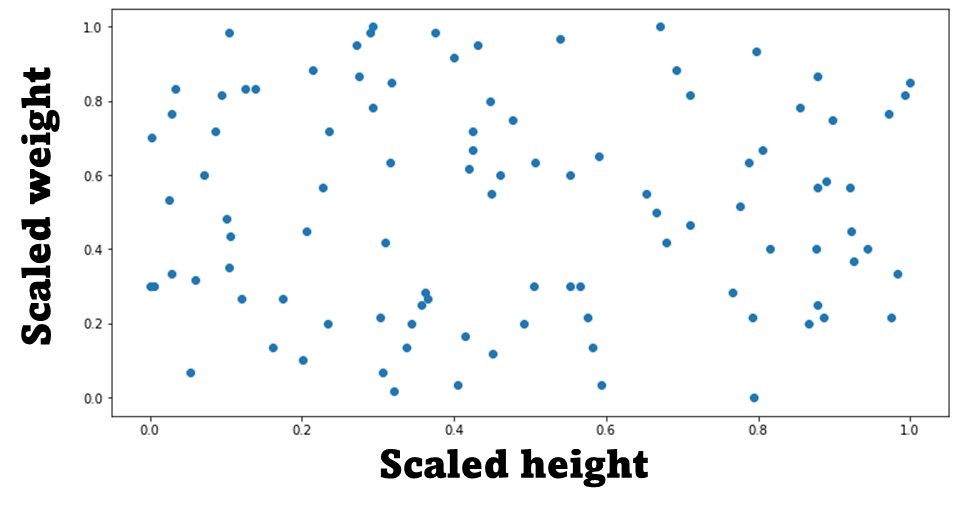
We have learnt how to use the MinMaxScaler Python object to effectively scale our data.
No products found.
Also, for other awesome books and courses about Python and Machine Learning, check out our reviews:
Book reviews:
- The 100 page Machine Learning Book
- Hands-On Machine Learning with Scikit-Learn & Tensorflow.
- Deep Learning with Python by Francois Chollet.
Courses
- Coursera: Machine Learning by Andrew Ng
- Complexity Explorer: Fundamentals of Machine Learning
- Udemy: Python for Data Science and Machine Learning Bootcamp.
Thanks a lot for reading, have a great day, and keep learning!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
