

Learn about the Lift Curve in Machine Learning, a great metric to asses the performance of our classification algorithms 👈
The goal of this post is to explain what the Lift curve in Machine Learning is, how it can complement other classification evaluation techniques like the ROC curve, and how it can be used to compare different models. It complements our previous posts The Confusion Matrix in Python and ROC in Machine Learning that asses the performance of Machine Learning classification tasks.
Al tough it is not necessary to know about it to understand the Lift curve (they are independent tools) but is is always nice to see how they can be used together.
Having said all this, let’s get to it.
The Lift Curve in Machine Learning & The Probability output of classification algorithms
When facing a binary classification problem (like for example identifying if a certain patient has some disease using his health record) the Machine Learning algorithms that we use generally return a probability (in this case the probability of the patient having the disease) which is then converted to a prediction (whether or not the patient has such disease).

The lift curve uses this returned probability to asses how our model is performing, and how well it is identifying the positive (1s or sick patients) or negative (0s or healthy patients) instances of our Dataset.
The Data
The Dataset used for this example is the UCI Cardiography Dataset which you can find here. It is not necessary to download the data to understand this post, but there is a link to the Jupyter Notebook with the code that I’ve used for the explanation at the end of this article in case you want to play around with it.
The goal of our model will be to classify patients that have a certain heart pathology. Lets see how our Lift Curve can help us evaluate the model.
No products found.
The Lift Curve in Machine Learning
The following Figure shows an example of how a normal lift curve looks:
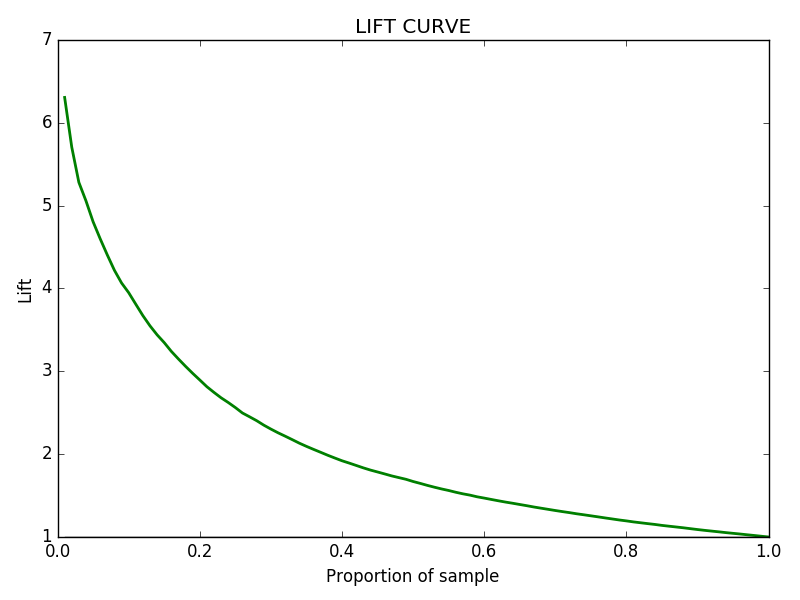
As we can see, on the X — axis we have the proportion of our sample that corresponds to a certain Lift, plotted on the Y — axis. The Lift is easily calculated as the ratio of 1s on a certain sample point, divided by the ratio of 1s on the whole dataset, which can also be viewed as the predictions that a random algorithm would be making.
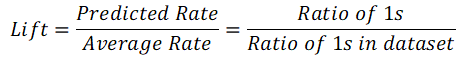
How to build the Lift Curve: Plotting the Lift Chart
Building a Lift Curve is very easy. First we must sort out the predictions of our model from highest (closest to 1) to smallest (closest to zero). In this way we have our population ranked by how likely they are to have the disease.

After this we calculate the ratio of 1s on the Dataset using the real known labels, and for each proportion of sample (the X — axis) we calculate the Lift using the formula described above, which is what we finally plot. The lift on each point is therefore calculated using the positive real labels of the proportion of the sample of the data up to that point and the total number of positive real labels of our data.

LEVEL UP FASTER
Get the ML Starter Kit
Everything you need to learn faster: full roadmap, project templates, datasets, and portfolio.
How to read the Lift Curve: Interpreting the Lift Chart
Let’s see how the Lift Curve can help us evaluate our model: in our example, we want to estimate how likely it is a patient has a disease. By ordering the data the way we have, the patients with the highest probability of having the disease will appear on the left of our graph, usually along with the highest Lift scores.
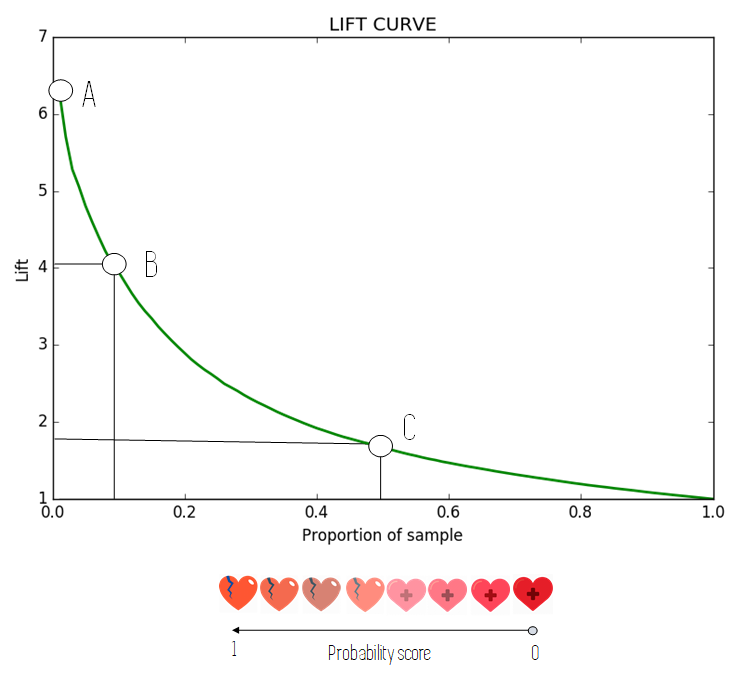
These patients would correspond with point A of the previous figure, which is sometimes called the Maximum Lift point. The general rule is that the higher this point is, the better our model is performing, as there is a lot of real positive labels in a proportion of our population which has a very high probability of being positive (which we know because we have ordered the data points in this manner).
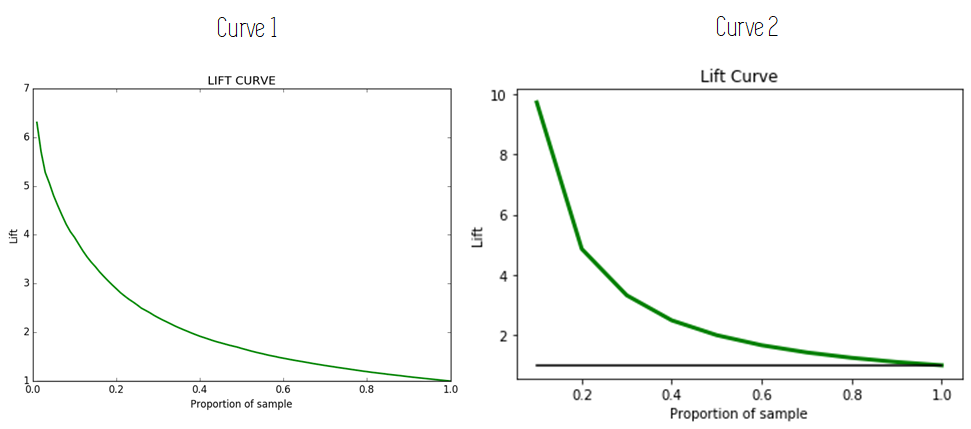
The Maximum Lift is a metric that can be quickly used to compare two models: the one with the highest Maximum Lift is generally better. The following figure shows this. Curve 2 has a higher Maximum Lift, so the model that corresponds to it is probably better.
For point B, we have chosen a sample including 10% of our population, where we can see that we have more than 4 times more of positive labels than the average. How do we translate this into useful information? Imagine that our records show that 10% of the patients had heart disease and 90% did not. The information on point B would be telling us that the 10% of our population with the highest chance of having the disease has about 4 times more proportion of diseases than the mean.
So in our example, that group of 10% of the population with the highest probability predicted by our algorithm would have around a 40% (4 times the 10% mean) proportion of sick patients.
Finally, point C is very similar to point B, but for a sample which includes the 50% of our population with the highest chance of having the disease. For this sample the proportion of sick patients is twice as much as the mean, so it would be a 20% proportion of sick patients.
One last interesting concept to explain is that of the Ideal Lift. This happens very rarely, when the start of the lift curve is flat, like in the following figure.

What this means is that until the Lift Curve starts to drop, as you make the proportion of sample larger, the Lift remains constant, so the group of your population that has the Maximum Lift, gets bigger and bigger until this drop happens, which is something very good.
Here you can find the code to plot a Lift Curve using the real labels of a set of data points and the corresponding predicted probabilities.
The Lift Curve in Machine Learning: Conclusion and Other resources
The Lift curve in Machine Learning, just like all other evaluation metrics is not an unique or perfect solution, however, like a ROC curve, it provides a quick way to get an estimate of how our algorithm is doing and a good tool to compare different models.
Lift curves are very useful in marketing models where we want to predict whether a certain audience will react to a specific marketing campaign: using the lift curve we can make a cut in a certain population size that is the most likely to react positively. Also, they can be used for similar purposes in models that try to predict if a person will default on a loan or payment and target only the sample with the highest impact.
Additional Resources:
- Lift Analysis – A Data Scientist’s Secret Weapon
- Cumulative Gains and Lift Curves: Measuring the Performance of a Marketing Campaign
- The ROC Curve in Machine Learning
- The Confusion Matrix in Python
- Review of the Python for Data Science Handbook
That is all, we hope you liked the post. If you did, please follow us on Twitter
No products found.
Tags: Lift Machine Learning, Lift Curve, Lift Chart Machine Learning, Lift Metric Machine Learning, Machine Learning Lift, Curve Lift.
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
