

Machine learning for text extraction with Python is one of the best combos out there for this task. With it, we can extract textual material from unstructured data quite effortlessly.
In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy.
So make sure to read till the end to absorb the maximum knowledge. Lets get to it!
Identify the Need
Before we go into coding things, first understand the need.
What type of text or information do you aim to extract? You are unlikely to produce an effective text extraction model if you aren’t well aware of what exactly you want to extract. Having a clear goal will help decide what approach to adopt down the road.
For instance, if you’re working within the field of digital media marketing, you might focus on extracting sentiment, customer feedback, or trending topics. Once you decide the need, follow the next steps.
Essential Libraries You’ll Use
To use Machine Learning for text extraction, you’ll need libraries to train and teach computer models about the text. Python has a network of libraries for tasks related to text processing and machine learning. The following are some of the most popular ones that you’ll need along the way:
- NLTK (Natural Language Toolkit) – It’s a toolkit that is comprised of several programs and libraries. It can help facilitate multiple tasks such as stemming, parsing, tokenization, labeling, and semantic reasoning.
- Pytesseract – It is a Python library that offers an interface to Tesseract’s Optical Character Recognition (OCR) engine.
- scikit-learn – The most widely Machine learning for text used for Python, scikit-learn is an open-source, free machine learning library. It has many useful tools for stats modeling and machine learning including regression, classification, and clustering. You can use it to teach computers and measure their learning progress.
- Pandas – This works best for model evaluation and machine learning algorithms.
- TensorFlow/Keras – It is well suited for tough text extraction tasks. It helps teach computers in a comprehensive way through artificial neural networks, similar to the brain.
Steps to Follow
Let’s start the process of using Machine learning for text extraction. Each of the following steps can’t be skipped. So pay equal attention to them.
Data Gathering and Cleaning
- Collect Relevant Data Sets – The first step starts with collecting pertinent data that you want computer models to learn from. Be sure to gather the right, quality data, because the quality of text extraction will depend on the data you feed to the model.
- Preprocess/Clean the Data – After collecting the relevant data, clean it so it is easily understandable by the computer model.
- Tokenization – Break text into shorter words or tokens. This makes it easier for computers to understand human language. It’s like breaking sentences or paragraphs into individual words that computers can easily process.
- Lemmatization or Stemming – It involves reducing words to their base form. The aim is to decrease the number of unique words so it is easy to understand and analyze.
We have provided a screenshot of the code you’ll need to follow to successfully implement this step:

In this example, we’ve taken a sample text which we’ll use to train the algorithm. Consequently, it’ll perform with higher accuracy to get editable content from images.
Model Selection and Training
Select Relevant Algorithms – Choose the right and appropriate algorithm that can best serve your specific text extraction needs. The following are some popular choices that are worth considering:
- Named Entity Recognition – Bidirectional LSTM-CRF or Conditional Random Fields (CRFs) are quite good at cataloging sequences and finding names in text.
- Relationship Extraction – RNNs (Recurrent Neural Networks) and SVMs (Support Vector Machines) work perfectly to extract relations between things.
Train the Model – After choosing the relevant algorithms, feed processed data into them and boost parameters. The selected model will analyze the provided data to spot patterns and comprehend the examples. Make changes in the parameters to improve its efficiency and accuracy. Keep adjusting the parameters until it brings the desired results.
Refer to the following code for selecting and training the model:

Here, we’ve selected a LinearSVC algorithm to train our model. This is better to classify text into different categories like punctuation, words, mathematical equations, and so on.
Model Evaluation
Gauge the Model Performance – To see how well the model has learned, use metrics like precision, accuracy, F1-score, and recall. Precision accesses how accurately the model labels things as important.
Accuracy measures how many times the model got it right. Recall indicates how many important units it found in total. The F1 score joins recall and precision into one.
Iterate and Refine – If you don’t get satisfying results, make changes and test the model again. Keep repeating this until it performs the way you intend it to. Doing this repeatedly will help ensure the model learns as much as possible and performs accurately.
Here’s an example of the code you can use to perform model evaluation:

For the provided code, we are going to evaluate the performance of our model using a text_clf.predict function. This is part of the scikit library that we discussed earlier.
For complex tasks, you may want to opt for deep learning models such as GPT-4o, or RoBERTa. Pretrained models can also be of help in streamlining training and boosting performance.
To show a finalized version of a text extractor, we have found a tool named imagetotext.io. This OCR web app has been developed using all the methodologies discussed above. It is capable of extracting editable text with the greatest accuracy since it’s already trained and evaluated for potential errors.
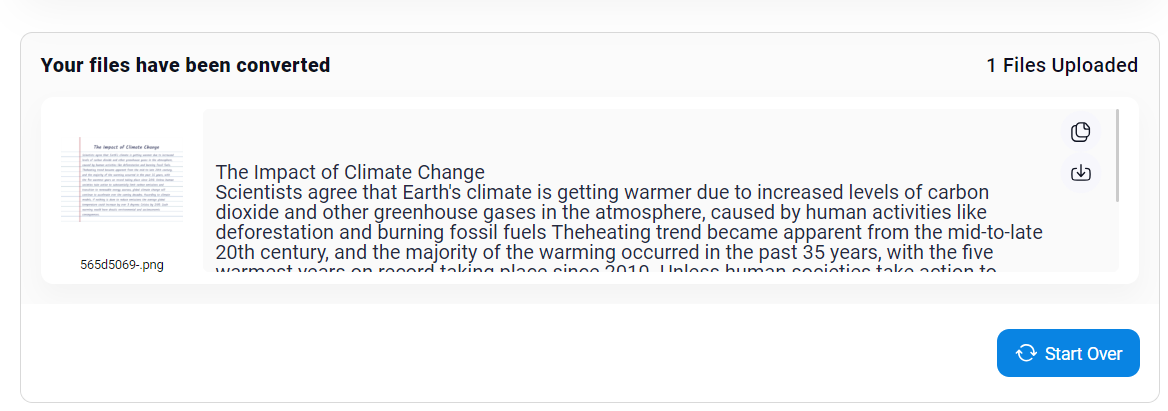
For a worked demonstration, we provided the tool with a screenshot containing text. The results we got were very satisfying, showcasing the level of detail to which you can train your text extractors.
No products found.
Final Words
Using machine learning for text extraction with Python is a novel approach to extracting textual material from unstructured data with the greatest accuracy. To build a machine learning model implementing this approach, you will first need to identify the need and utilize necessary libraries like NLTK, pandas, and scikit-learn. Other steps involve data collection and cleaning, model selection and training, and model evaluation.
Throughout this process, maintaining a growth mindset is important, as it will help you adapt and improve your model continuously. We have explained the topic in detail so you don’t have any doubts left. Anyone can follow this guide to use machine learning for text extraction with Python.
Enjoy, and keep learning!
#Machine learning for text #Python for OCR
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
