

What is Transfer Learning? Where can I use it? Why should I use it? How can I use it? What are some Transfer Learning examples? Read On to find out!
Introduction
Transfer learning (TL) is a widely used technique in the Machine Learning world, mostly in Computer Vision and Natural Language Processing.
In this post, we will explain what it is in detail, when it should be used, why it is relevant, and show how you can use it in your own projects.
Once you’re ready, lay back, relax, and let’s get to it!
TL;DR!
- What is transfer learning?
- Why is transfer learning awesome?
- When should I use transfer learning?
- How can I use transfer learning?
- Conclusion and further resources.
1) What is Transfer Learning?
We are going to see various definitions of the technique, to clarify what it is from different angles, and ease the understanding.
Starting from the bottom, just from the name we can get a rough idea of what transfer learning might be: it refers to the learning of a certain task starting from some previous knowledge that has already been learned. This previous knowledge has been transferred from the first task, to the second one.
Remember when you learned how to multiply? Your teacher probably said something like ‘Multiplying is just adding X times’.
As you already knew how to add, you could easily multiply by thinking ‘Two times three is just adding two three times. Two plus two is four. Repeat once more with the previous result to reach three additions. Four plus two is six. This means that two times three is six! I am a genius!’
It might not have been exactly this, but the mental process was probably something similar. You transferred the learning you had done in addition to learn how to multiply.
At the same time, you probably learned the multiplication tables, which allowed you to later multiply easily without having to go through the whole addition procedure. The start, however, was knowing how to sum.
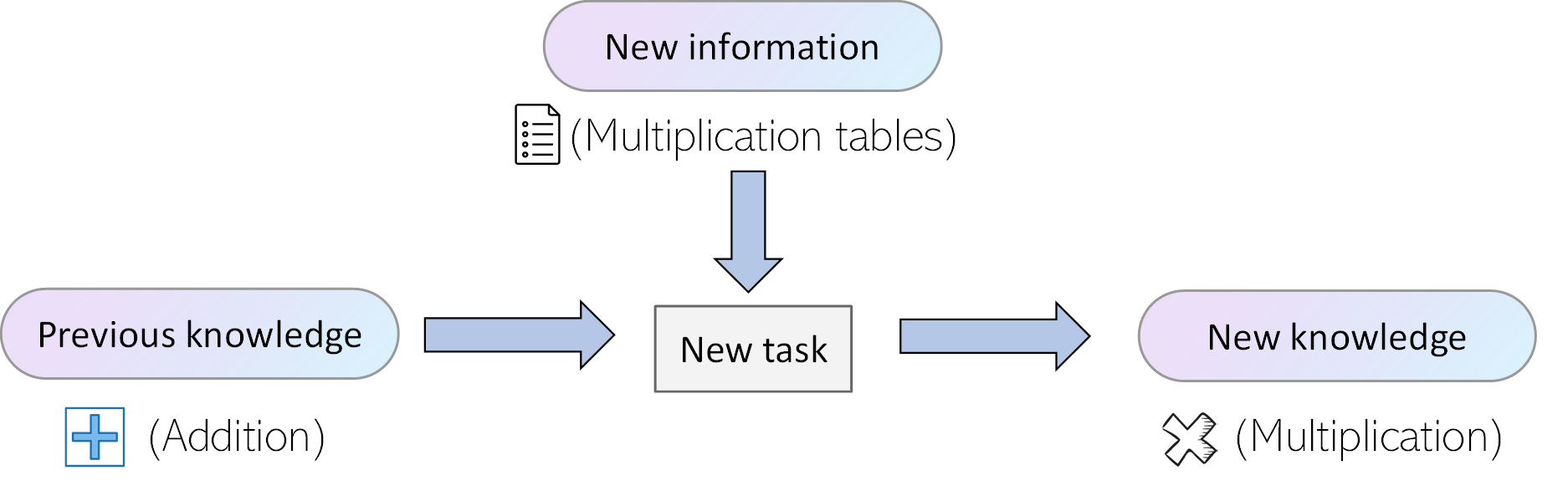
In the famous book Deep Learning by Ian Goodfellow et al, Transfer Learning is depicted in the following way. You can find an awesome review of this great book here.
Transfer learning and domain adaptation refer to the situation where what has been learned in one setting … is exploited to improve generalization in another setting
As you can see, this last explanation is a bit more precise but still holds with our simple, initial one: some skill that has been learned in one setting (addition) can be used to improve performance or speed in another setting (multiplication).
Lastly, before we see why transfer learning is so powerful lets see a more formal definition, in terms of Domain (D), Task (T) and a feature space Xwith a marginal probability distribution P(X). It goes as follows:
Given a specific Domain D = {X, P(X)}, a task consists of two components: a label space Y, and an objective predictive function f(•), which is learned from labelled data pairs {xi, yi} and can be used to predict the corresponding label f(x) of a new instance x. The task therefore can be expressed as T = {y, f(•)}.
Then, given a source domain Ds, and a learning task Ts, a target domain Dt, and a learning task Tt, transfer learning aims to help improve the learning of the target predictive function ft(•) in Dt, using knowledge in Ds and Ts. [1]
Awesome! Now we have seen 3 different definitions in increasing order of complexity. Let’s see a quick example to finish grasping what Transfer Learning is.
Transfer learning in Computer Vision
Lets see some transfer learning examples! Computer Vision is one of the areas where this technique is most widely used because of how CNN algorithms learn to pick up low level features of images which can be used along a different range vision of tasks, and also because of how computationally expensive it is to train these kinds of models. You can find awesome Computer Vision Tutorials here, and great data sets to build your own projects here.
As we will see later, there are strong reasons to use Transfer Learning in this area, but lets first see an example. Imagine a Convolutional Neural Network that has been trained for the task of classifying different common objects, like for example the Common Objects in Context (COCO) Dataset.
Imagine we wanted to build a classifier to perform a much more specific and narrow task, like identifying different types of candy (Kit-Kats, Mars Bars, Skittles, Smarties), for which we had a lot fewer images.
Then we could most likely take the network trained on the COCO dataset, use Transfer learning, fine tuning it using our small data-set of candies, and achieve a pretty good performance.

Alright, after this quick example, let’s see why we would want to use Transfer Learning.
2) Why is Transfer Learning awesome?
In the previous example, we saw a couple of the benefits of transfer learning. Many problems are very specific and it is very hard to find a high volume of data to tackle them with a medium-high success.
Also, there is a fundamental concept in Software development that I think if adopted properly can save us all a lot of time:
We don’t have to reinvent the wheel!
The AI community is so big, and there is so much public work out there, data sets, and pre-trained models, that it makes little sense to build everything from scratch. Having said that, these are the two main reasons why we should use transfer learning:
- Training some Machine learning models, especially Artificial Neural Networks that work with images or text, can take up a lot of time, and be very computationally expensive. Transfer learning can ease up this load by giving us a network that is already trained and only needs some posterior fine tuning.
- Datasets for certain tasks (like for example a Data set of classified candy bar images, or specific data sets for natural language processing problems) are very costly to obtain. Transfer learning allows us to obtain very good results in these narrow tasks with a much smaller data set than what we would need if we faced the problem without it.
Don’t forget, Transfer Learning is an optimisation: a shortcut to saving time on training, solving a problem that you wouldn’t be able to solve with the available data, or just for trying to achieve better performance.
3) When should I use Transfer Learning?
Okey Dokey! Now that we know what Transfer Learning is, and why we should use it, let’s see WHEN we should use TL!
First of all, to use Transfer Learning, the features of the data must be general, meaning that they have to be suitable for both the source and the target tasks. This is generally what happens in Computer Vision, where the inputs to the algorithms for training are the pixel values of the images, and their specific labels (classes or bounding boxes for detection). Many times this is what happens in Natural Language processing too.
If the features are not common to both problems, then applying Transfer Learning becomes much more complex if possible at all. This is why tasks which have structured data are harder to find in Transfer Learning as the features must always match.
Secondly, as we saw before, Transfer Learning makes sense when we have a lot of data for the source task, and very little data for the posterior or target task. If we have the same amount of data for both tasks, then transfer learning does not make a lot of sense.
Third and last, the low level features of the initial task must be helpful for learning the target task. If you try to learn to classify images of animals using transfer learning from a data set of clouds, the results might not be too great.
In short, if you have a source task A, and a target task B for which you want to do well, consider using transfer learning when:
- Task A and B have the same input x.
- You have a lot more data for task A than for task B.
- Low level features from task A must be helpful for learning task B.
Alright! Now that we now What, Why and When, let’s finish with the How.
4) How can I use transfer learning?
For using this kind of learning strategy there are two main alternatives: Using a pre-trained model, or building a source model using a large available data set for an initial task, and then using that model as the starting point for a second task of interest.
Many research institutions release models on large and challenging datasets that may be included in the pool of candidate models from which to choose from. Because of this, there are a lot of pre-trained models available online, so there is a high chance that there is one that is suitable for your specific problem.
If not, you can grab a data-set that might be similar to yours, use that to train an initial source model, and then fine tune that model using the data you have available for the second task.
In either way, a second training phase with our specific data is needed to tune the first model to the exact task that we want to perform. Let’s see how this happens in the context of an ANN:
- We take the network with its structure and pre-trained weights.
- We remove the last layer (the output layer).
- We replace this layer with a different output layer or a combination of different layers.
- We perform a training phase with the data we have for the second task. This second training can modify only the weights of the newly added layers (recommended if we lave very little data) or the weights of the whole network.
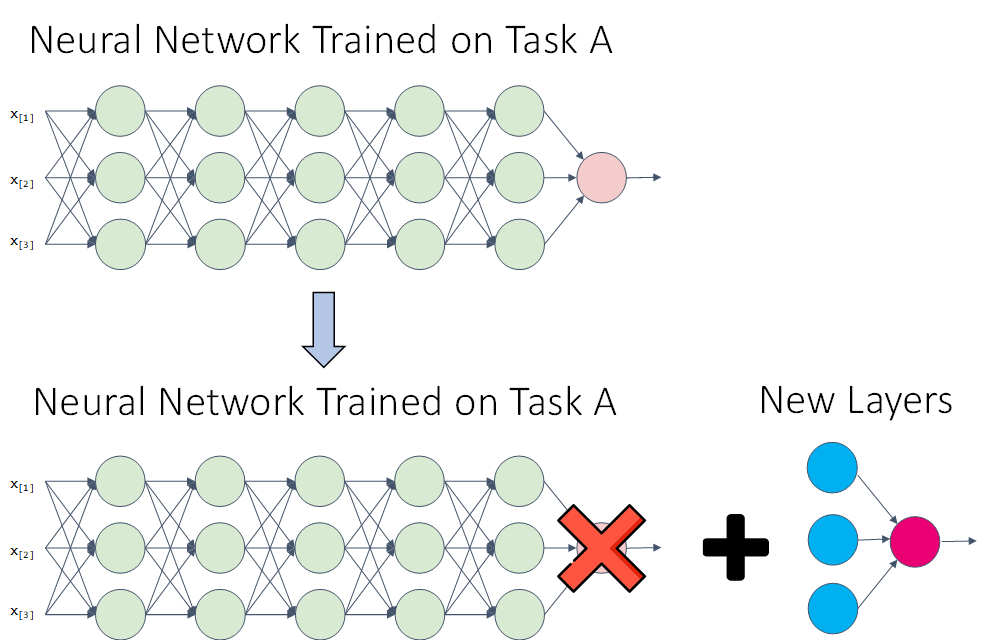
In practice, we rarely have to do this manually, as most frameworks that allow for the use of Transfer Learning handle this transparently for us. In case you want to use Transfer Learning for any project, here are some awesome resources to get started:
- Darknet Computer Vision Library.
- Many NLP projects that use word embeddings such as GloVe and Word2Vec allow the option to fine tune the embedding to the specific vocabularyIf you don’t know what Word embeddings are, you can check learn about them here.
- Mask R-CNN for object segmentation also uses TL from the COCO dataset.
5) Conclusion and Additional resources
That is it! As always, I hope you enjoyed the post, and that I managed to help you understand what Transfer learning is, how it works, and why it is so powerful.
If you want to learn more about Machine Learning and Artificial Intelligence , you can check out this repository for more resources on Machine Learning and AI!
Here you can find some additional resources in case you want to learn more about the topic:
- Cafe model Zoo: GitHub repository with a wide range of pre-trained models.
- Andrews Ng Video on the topic.
- Paper: A Survey on Deep TL.
- Another Repository with a lot of further resources on Machine Learning and Artificial Intelligence.
Thank you for reading and have a fantastic day!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
