Level up your Machine Learning journey — Roadmaps, tutorials, and AI projects
Explainable Artificial Intelligence
Learn about Explainable Artificial Intelligence, how to create explainable Machine Learning models, and Interpretable AI!
Explainable Artificial Intelligence is one of the hottest topics in the field of Machine Learning. Machine Learning models are often thought of as black boxes that are imposible to interpret. In the end, these models are used by humans who need to trust them, understand the errors they make, and the reasoning behind their predictions. Giving them some kind of explainability is very important. In this post we will explore what Explainable AI is, why it is relevant, and see some examples of how we can achieve it using real data.
So, what is Explainable Artificial Intelligence?
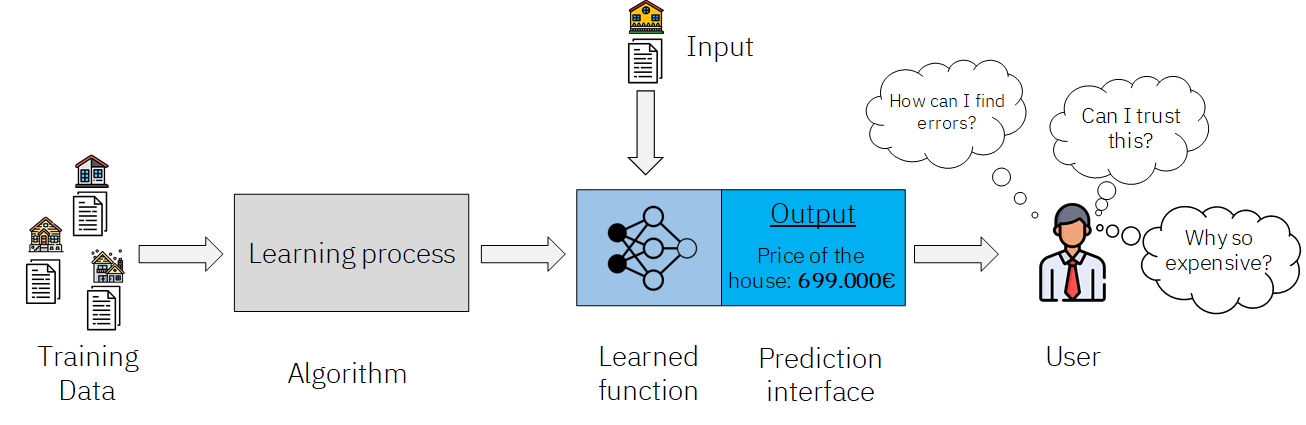
The current structure of a Machine learning workflow, from training to deployment in a productive environment for its use is something like this:
Figure 1: ML Workflow.
The explanation of this image is the following: we use some data to train a model through an specific learning process. This learning process results in a learned function, which can be then fed inputs, and it outputs a prediction in an specific interface, which is what the final user sees and interacts with.
In the previous example we used housing data to train a model, which ends up being an Artificial Neural Network, but could have been anything else: from a decision tree, to an SVM or a boosting model.
After this function has been learned, we can then feed it new inputs, which in our case are new houses, and it returns a prediction about the price of the input house. Finally a user, which in this case would be the owner of a real-state company, sees the output and makes decisions or starts certain actions.
The problem here, as we can see by the doubts of the user, is that the prediction comes with no justification.
Before deploying any Machine Learning model we are more or less aware of its error (as it is what our learning process tries to reduce), but this only gives us a certain number in the loss scale, or quantifies a certain numerical distance between the labels in the data and the predicted labels before deployment. Can we trust this error above everything?
Our model can have a low error, and still have a certain bias, or make intriguing predictions from time to time. It is probably a good idea from a business perspective to understand these weird predictions as they might tell us something we don’t know. They could also mean there is something wrong with the model and that it has to be replaced.
Even if there is no actual problem with the predictions, we would like to understand why the model is saying what it is saying. You can have good results on test data, and get pretty accurate predictions, but sometimes that is not enough.
All these previous questions are the reasons that make Explainable AI so desirable. We will learn what it is by seeing how it would fit in within our previous example.
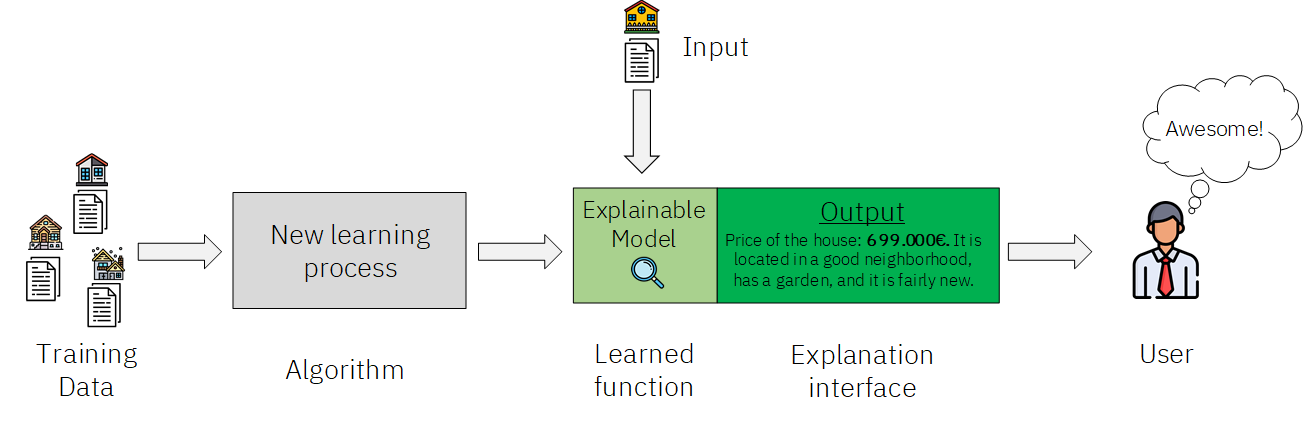
Figure 2: Explainable AI incorporated to the workflow.
Lets see what is happening here to clarify what is Explainable AI. This time, we have used a new and different learning process to learn a function associated to an explainable model. This means that this function not only has the capacity of giving us a prediction, but also of explaining why it makes that prediction. The new explanation interface displays additional information that can give our user some insights into why such prediction was made. Later in this article, we will see how this can be achieved with some real examples.
Why is Explainable AI so important?
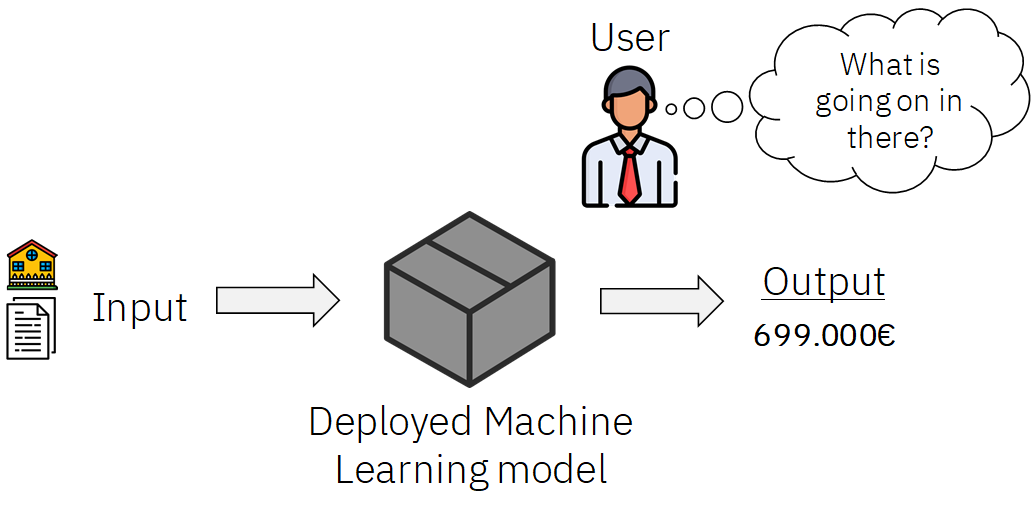
When we train AIs with lots of parameters to which we apply transformations, we end up turning the whole process of pre-processing and model building into a black box model that is very hard to interpret. Maybe the Data Scientist or Machine Learning engineers that built the model are aware of the transformations and operations that the data goes through, but for the final user these are completely magic.
Figure 3: Machine Learning models seen as a black box.
He simply gives his model an input, and he gets a prediction that he should trust. Is this possible without knowing what is happening under the hood, and without any further explanation?
Since the start of the path to the mainstream adoption of AI, it has been alright to train machine learning models with a black-box approach —as long as they give us good results, it doesn’t matter if we can’t explain them. Now, the focus is slowly turning towards the transparency and explanability of these models. We want to know why they come up with the predictions they output. This transition is coming for various reasons:
Understanding what happens when Machine Learning models make predictions could help speed up the widespread adoption of these systems. New technologies always take time to become mature, but it definitely helps if they are understood.
It makes users become increasingly confortable with the technology, and removes the magical veil which seems to surround AI. Having users that trust the systems that they are using is of upmost importance.
For some sectors like insurance or banking, there are sometimes company level or even legislative restrictions that make it a must for the models that these companies use to be explainable.
In some other critical areas, like for example medicine, where AI can have such a great impact and amazingly improve our quality of life, it is fundamental that the used models can be trusted without a hint of a doubt. Having a Netflix recommendation system that sometimes outputs strange predictions might not have a very big impact, but in the case of medical diagnosis, uncommon predictions could be fatal. Providing more information that just the prediction itself allows the users to decide whether they trust the prediction or not.
Explainable models can help their users make better use of the outputs such models give, making them have even more impact in the business/research or decision making. We should always have in mind that like any other technology, the goal of AI is to improve our quality of life, so the more benefit we can extract from it, the better.
There are definitely more reasons than just these 5; the topic of Explainable AI is wide and varied, but after seeing why it is so desirable to have explainable Machine Learning models, lets see what normally happens.
Generally, the normal mindset is the one mentioned above — we want results, so our Machine Learning models have to necessarily have great performance. Some Machine Learning models usually perform better than others, while also having different interpretability.
A Random Forest model usually outperforms a Decision tree, but the former is much harder to explain than the latter. The following figure shows this tendency: as performance increases explainability tends to decrease. What we want is to go from the X to the O, that is, increasing explainability without hurting model performance much.
Figure 4: Explainability vs Performance of different Machine Learning models. Actual and Desired situations.
To end, lets see some examples of how we could build an explainable AI system, and the kind of information that we would get from it.
Examples of explainable Artificial Intelligence
As mentioned earlier, the interpretability of a Machine Learning model is inherent to it. While Artificial Neural Networks are very hard to interpret, Decision Trees allow for simple interpretations. Neural Networks however, are much more powerful.
If we want to reach explainable AI, there are a couple of things we can do:
Use an explainable model, like a Decision tree.
Add a layer of interpretability on top of a harder to explain model, like a Random Forest.
With 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa, this competition challenges you to predict the final price of each home.
As the goal of this post is to detail how Explainable AI can be applied, this data has been largely simplified and we have only kept the numerical variables, doing a very light pre-processing step, and models have been used with the default hyper-parameters and no further optimisation.
1) Using a Decision Tree
As we mentioned before, Decision Trees are one of the easiest to interpret Machine Learning models. They way to do this is very simple, and it is best understood if we know how decision trees are built: through recursive splitting of the data into smaller and smaller groups, which end up in our leave nodes.
If you are unsure of how decision trees work, you can learn about them on our Tutorials Page.
When a decision tree is used to make a prediction, starting from the root node until a leave node is reached, (and passing through the necessary intermediate nodes) a certain variable of the data is evaluated at each node, and our data sample goes left or right depending on the value it presents for such variable.
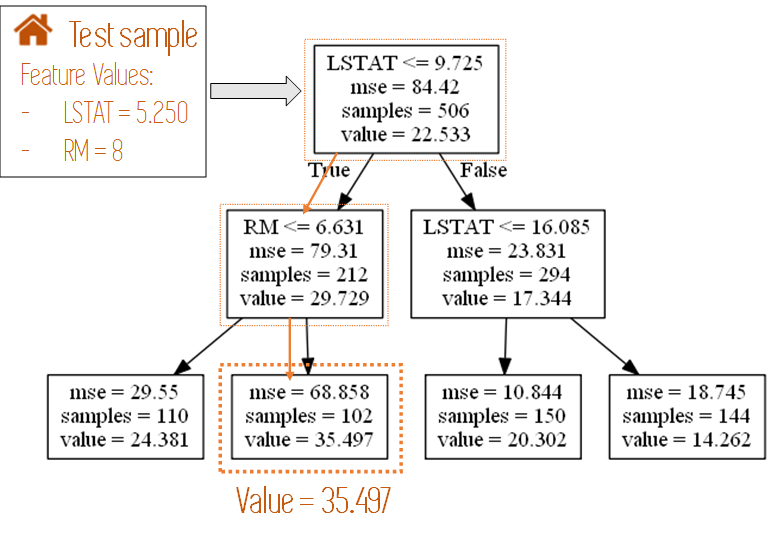
The following Figure depicts an example of this for a tree built on some housing data using only two variables. First it looks at the value of the variable LSTAT and then at the value of RM, to end up in the final leave node.
Figure 5: Example of how an input data sample would move through a Decision Tree with just 2 features.
Note: This is a random tree built for another project, not for our actual data.
How can we explain a prediction using tree? Easy, we just have to follow the path that the sample makes through the tree, and which makes it end up in the leave node it does.
For our actual data set, we built a Decision Tree of depth 8 and fed it a prediction. It’s path through the tree until it reached its correspondent leave node (where the prediction is made) was the following:
Figure 6: Decision Tree path for a random Input of our test data
Something like this is what a Data Scientist can get out of a Decision Tree model, along with the prediction itself, which in this case was 212542$.
Now, if we know what each of the variables mean, and we team up with a domain expert, we can create something much more powerful, as deeper insights can probably be extracted from this information.
From the previous path we can see that it is a high quality house (between 6.5 and 7.5 in OverallQual variable), limits for the dimensions of the basement, ground and 1st floors (from basement –TotalBsmtSF, 1st floor –1stFlrSF, and ground area — GrLivArea) and that it also has a large garage and it has been remodelled after 1978 (from GarageArea and YearRemodAdd variables).
With all of this knowledge, the domain expert can build a text for each variable and join them together, like so:
“High quality building, with a ground living area smaller than 1941 squared feet, a basement with less than 1469 squared feet, a Garage of more than 407 squared feet, and a first floor of more than 767 squared feet. It has also been remodelled after the year 1978. Because of this its predicted price is of 212542$.”
This, in broad terms, would be the reason backing up the numerical prediction of the price. For further information the actual values of those variables, along with others could be included in the text.
With all of this information we can give the user two things: first of all, using the path, we can give him a general reasoning behind the prediction that the model gives. Also, a more complex explanation than the one above could be crafted, as in the example above we are just listing raw information that we get from the variables and their values, however, a coherent and more elaborate text involving business reasoning could be built.
Imagine an example where we have the previous path and also variables like the ZIP code. We could craft a text like:
“High quality remodelled house in a good neighbourhood, with garage and three floors, these houses are being sold a slight percentage above normal Market prices. Because of this the predicted price is of 212542$”
Using this approach we could also include the values of other variables that are not in the path of the decision tree but that we consider relevant in a separate text, like for example the type of heating, air-conditioning availability and electrical system.
Cool right? Lets finish by seeing a more complex approach to explainability.
2) Adding a layer of Interpretability: Shapley Values
Decision trees, however, have one key weakness: what they gain in explainability they loose in prediction capabilities. They are simple models that usually don’t get the best results.
If we train a Random Forest model using the same data and compare the errors (Mean Absolute Porcentual Error or MAPE) we see the following:
Figure 7: MAPE comparison for both models.
The error of the Decision Tree is almost double that of the Random Forest model. We can also see this by comparing the predicted price by both models with the actual price of the house: The Decision Tree predicted a price of 212542$, our Random Forest predicted a price of 206049$, and the actual price of the house was 208500$. The Random Forest did a better job than the lonely tree.
So, how do we explain a more complex model, like a Random Forest? What we do is use our complex model to make the predictions and then add a layer of interpretability on top of it, like shown in the following figure:
Figure 8: Adding an interpretability layer on top of a Black Box model
From the same input we generate an accurate prediction using a complex model, and a good explanation using the explanability or interpretable layer. What is in this layer? It could be various things: we could use a Decision Tree, just like in the previous example to generate the explanation, however, that would be the most simple thing and we are looking for something more powerful and accurate.
In this example, we will use the Shapley Values. Shapley values come from Game Theory, and I wont go too much into the detail of how they are calculated. Basically what they do is reflect the significance of the contribution of each player (feature in our Machine Learning case) in an specific cooperative game (making a prediction in our Machine Learning case).
We can calculate these values for all the variables in our feature set, and get for each prediction that we make the features that are most relevant for that specific prediction.
In Python, the SHAP library allows us to easily compute a more complex version of the Shapley values for an specific input. For this we just have to train the Shapley Explainer with the same training data that we used to train the model, and specify which kind of model we used, which in our case was a Random Forest. Lets see what the explainer outputs for the same observation that we used for the Decision Tree:
Figure 9: Output of Shapley Values
How do we read this Figure? Very easy. The variables are associated to bars with certain sizes and one of two colours: pink or blue. Where these two colours meet, we can see the predicted price for the house (206049$ as stated before) by our Random Forest model. The variables closest to where pink and blue meet are the ones with the most influence on the specific prediction.
The variables in pink, with their corresponding values,contribute to increasing the price of the house, while the ones in blue with their corresponding values contribute to decreasing the price. As we can see here, the variable/value tandem that most contributes to increasing the price of the house is the OverallQual variable with a value of 7.
The quality of the house in this case and the year it was built (2003) are the most relevant positive characteristics of the house. The small values of the areas of the basement and first floor are the most relevant negative characteristics. Together, all these variables and their values justify the prediction.
This information can be extracted in plain text, and approaches can be taken to make a legible explanation like in the decision tree example, but this time using a more accurate and complex model, as they explanation in the trees are limited by the leave nodes we get and the paths that end up in them.
Note: in both cases (the decision trees and the Shapley Values), the explanations are for an individual register of data. We are not using something like the overall feature importance of the model, which also gives very valuable insights onto how our model behaves, but that is model specific and doesn’t go down to the individual prediction level.
There are other techniques for adding interpretability layers like Permutation Importance or LIME, but they won’t be covered in this post, as I think that our goal of highlighting the importance of Explainable Artificial Intelligence, detailing what it is, and showing some examples, has already been done.
Conclusion
We have seen what Machine Learning explainability or Explainable Artificial Intelligence is, why it is so relevant, and various ways to achieve it. It is one of the hottest research topics in AI, and you can find more information about it on our Tutorials Section.
For going even deeper onto the topic, you can find some great books about Explainable Artificial Intelligence on Amazon: