

Learn what feature selection is, why it is important, and how you can use it.
In this article we will explore the importance of feature selection for Machine Learning.
Which features should be used to create a predictive Machine Learning model?
This is a question that every Machine Learning practitioner should consider when studying the creation of a model for a certain application.
Somehow, the general belief is that more features equals better model performance, however, this is far from being true.
What is Feature Selection in Machine Learning?
Feature selection for Machine Learning consists on automatically selecting the best features for our models and algorithms, by taking these insights from the data, and without the need to use expert knowledge or other kinds of external information.
Automatically means that we don’t hand pick the features, but instead we use some algorithm or procedure that keeps only the most important features for our model and its application domain.
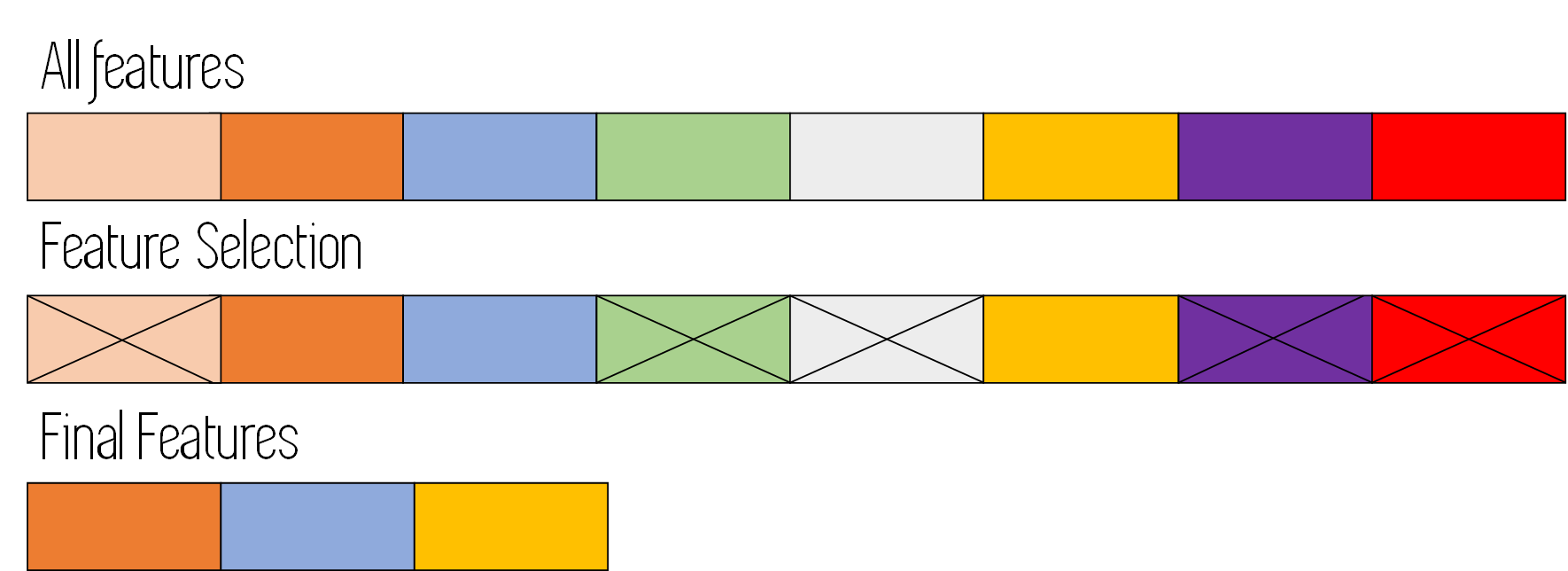
It is important to know here that expert knowledge of the application domain that the model is being built for is very important, as it allows us to better understand the data that is going to be used, and therefore gain some intuition about which features will probably be important, and which should be discarded.
The study of the features to eliminate from our models is very important. Features that are present in our initial training data, but that might be introducing some kind of ‘future’ information into the model should be removed, as they will probably be biasing the results, and we will probably not have them available at execution time.

This production or execution time availability should be considered for every feature, not just the ones that might contain ‘future’ information. To make it crystal clear, lets see an example of one of these type of features:
Example of ‘future’ feature: Imagine we are building an ML model to calculate the probability that a certain football team will win a match at half time, given some statistics for that match.
For this, we have to train the model using data from previous complete matches (as we need to know if they have won or not at the end of the match; this would be the target of our model), however, we should only use features/variables that are taken from the first half of the match, as those are the features that we would have available at the execution time of the model.
Also, if we used training data from lets say, minute 80, we would be introducing features into our model that would be biasing our ‘half time’ algorithm; aside from not actually having that variable truly available when we use the model.
Why should we do Feature selection in Machine Learning?
Alright, now that we know what feature selection in Machine Learning is, lets see why we should use it when training a model:
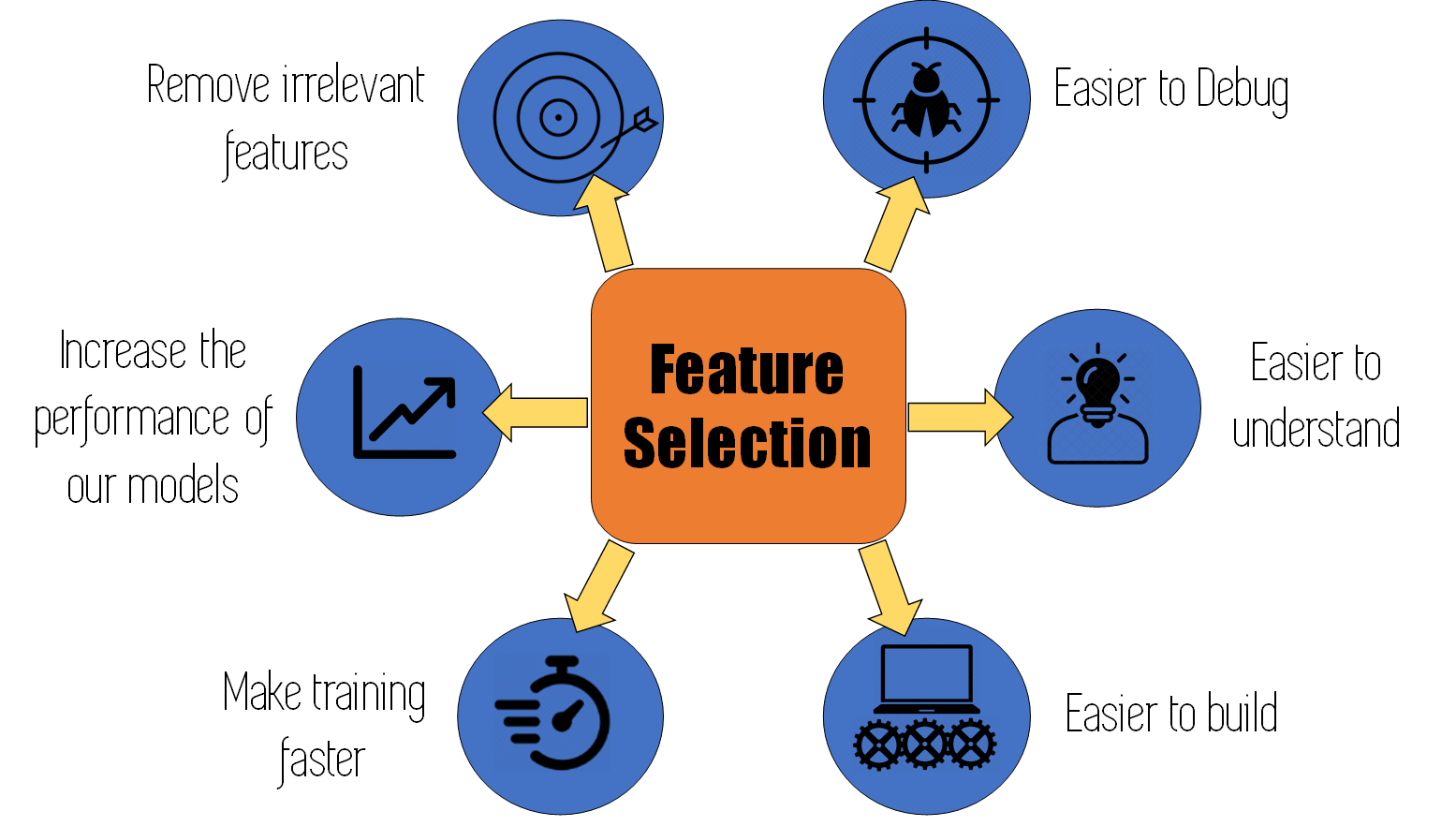
- Using feature selection we can remove irrelevant features that would not be affecting or changing the output of our model. If we try to predict the price of a house in Spain, using variables that include the weather conditions in China, these variables will probably not be very useful.
- These kind of irrelevant features can actually decrease the performance of your model by introducing noise.
- Less features usually means faster training models: for parametric models like linear or logistic regression, it means there are less weights to calculate, and for non-parametric models like Random Forest of Decision trees, it means there are less features to evaluate at each split.
- When putting models into production, less features means less work for the team building the application that will use the model. Using feature selection we can reduce the integration time for an application.
- When we keep the most important features, discarding the ones that our feature selection methods advise us to remove, our model becomes simpler, and easier to understand. A model with 25 features is a lot simpler than a model with 200 features.
- Once the application has been finished, and is being used periodically, a model with fewer features is a lot easier to debug in case of abnormal behaviour than a model with a lot of features.
Example of ‘abnormal’ behaviour: Imagine we have built a model to predict the probability of certain hospital patients having heart disease, and suddenly it starts predicting that everybody is sick. This problem can be originated by some variable that is getting informed in a different way than it was in the training data.
Maybe some porcentual value was given as decimal (0.75) in the training data and because a change in how IT manipulates this data, we are receiving it as an integer now (75, meaning 75%). This will obviously make our model behave weirdly, as it is expecting a number between 0 and 1 and its getting something completely different.
If we have to go through 200 variables to see which one is causing the problem, we will have to work a lot more than if there is only 10 variables.
How to do Feature Selection in Machine Learning
There are many ways to do feature selection, and many of them are implicitly included in the data cleaning phase that any project should have previous to the construction of a model.
- For example, eliminating features with a high percentage of not informed values, which is done in the data-cleaning phase can already be seen as part of the process of feature selection.
- Other steps of this process that could be considered feature selection are eliminating correlated variables (features that are redundant or explain the same information) and removing features with a very high percentage of similar values or features with a unique value. This is known as correlation based feature selection.
- Some regularisation techniques (techniques to reduce over-fitting) like LASSO, can also be used for feature selection, as they converge to weight values close to zero for the features that are not relevant to the problem.
- Algorithms like Random Forest or other ensembles can be used for feature selection as well. Most of these algorithms have a way to rank the importance of the features that take part in our models. To do feature selection we can make an initial model using one of these algorithms and all of our features, rank them by order of importance, and keep the top X Nº of features to use in our final model.
The use of these kind of models for feature selection will be discussed in the next post. When using them, it is interesting to plot graphs like the following one:
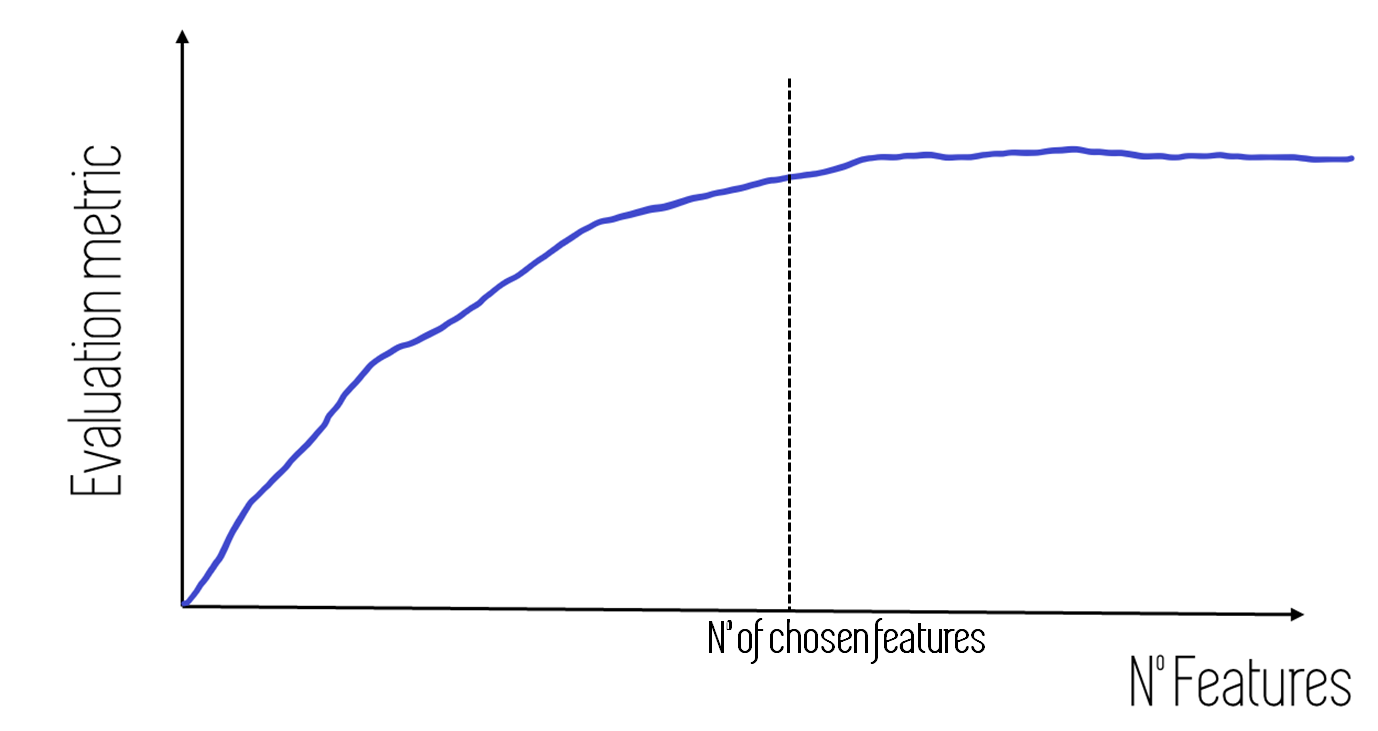
The previous graph shows the performance increase of a Machine Learning model as we add features in order of importance (the first model is trained using only one feature: the most important one. The second model is trained using the two most important features and so on…)
By using a graph like this we can decide where to cut, making a compromise between the performance of our model and the number of used features.
Lastly, more statistically complex methods like the BORUTA feature selection technique or mutual information feature selection methods.
To end, it is important to mention that feature selection is not the same as dimensionality reduction techniques like Principal Component Analysis (PCA). Dimensionality reduction techniques generally reduce the number of features of your data by combining the initial features to form new ones, whereas feature selection techniques select a subset from the initial set of features without modifying them.
Conclusion and Other resources
Feature selection is a very important step in the construction of Machine Learning models. It can speed up training time, make our models simpler, easier to debug, and reduce the time to market of Machine Learning products.
Also, there are books on feature selection like which really go deep into the subject, in case you want to know A LOT more:
No products found.
- The book Feature Selection for Knowledge Discovery and Data Mining (Springer)
- Or Feature Engineering and Selection: A practical approach for Predictive Models (Kuhn, Johnson)
- Or the paper ‘Feature Selection in Machine Learning, a new perspective‘, which is truly awesome.
Also, take a look at our Machine Learning books section to find more general books that include these topics.
We hope you enjoy these resources, and that you liked the post!
Thank you so much for reading How to Learn Machine Learning! Have a great day!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
