

You train a model, run cross-validation, and the score looks great. You ship it. A month later the model is making bad calls and that great score is nowhere to be found. If your data has a time order to it, this happens more often than people admit, and the cause is usually the cross-validation itself.
Here is the short version of why, and a small fix.
What k-fold assumes
Plain k-fold cross-validation, the kind you get from scikit-learn’s KFold, cuts your rows into chunks, trains on some chunks, and tests on the rest. It repeats this so every row lands in the test set once. The whole idea rests on one assumption: the rows are independent. Shuffle them, split them, and nothing leaks from train into test.
That assumption is fine for a table of customers where each row stands on its own. It falls apart the moment your rows are points in time.
Why time breaks it
Say you predict tomorrow’s price from the last five days. Two rows sitting next to each other share four of those five days. Their labels overlap too, because a label that takes a few days to resolve reaches into its neighbours. So when k-fold puts one row in training and the next one in testing, the model has basically already seen the answer. It did not learn a pattern. It memorised a neighbour.
The score that comes back is not skill. It is leakage wearing a skill costume.
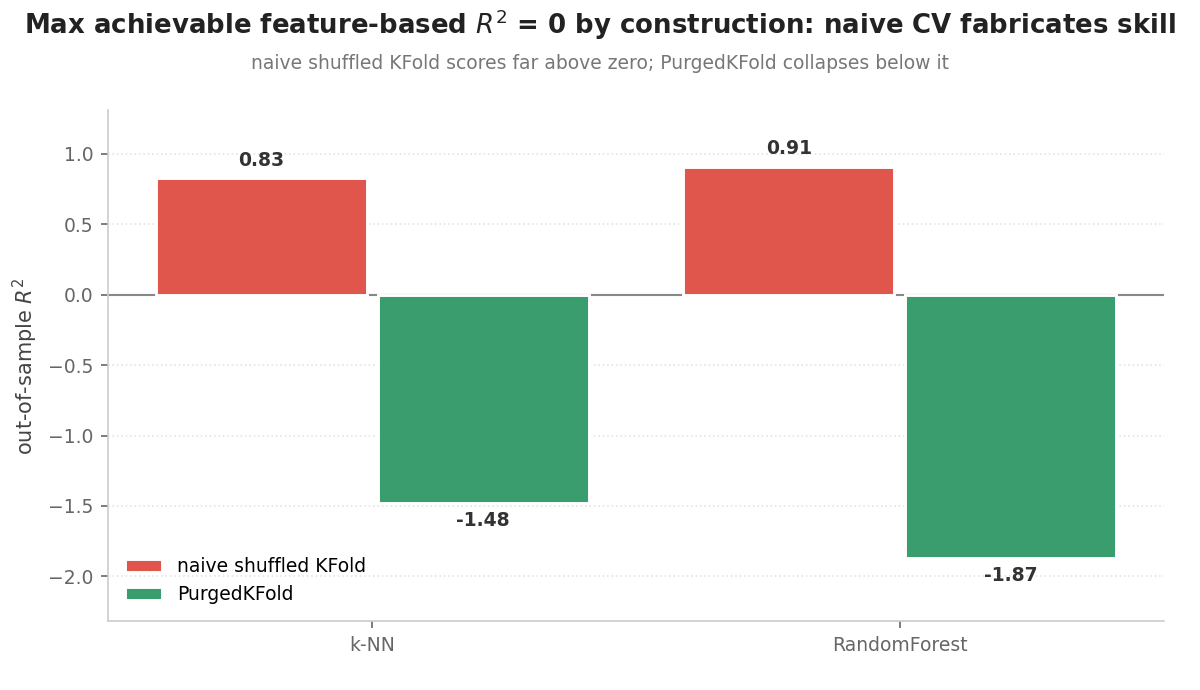
The clearest way to see this is with a target that nothing can predict. Build a series where the label is pure noise, then push a normal RandomForest through shuffled k-fold. You will often get an R squared around 0.9, which is impossible for noise. The split handed the model the answer. Now swap in a split that removes the overlap and the same model drops below a coin flip, which is the honest result.
The fix: purge and embargo
The fix is not a fancier model. It is a fairly small change to the split.
Two ideas do most of the work:
- Purging. Before testing on a block, drop any training rows whose label overlaps that block in time. No shared answers.
- Embargo. Also drop a short window of training rows right after the test block, because data that close is still correlated with it.
Keep the time order and cut the rows that leak. Then the model has to earn its score.
You can write this yourself, and it is a good exercise. A small library called purgedcv does it for you. It plugs into scikit-learn the same way KFold does, so you pass it to cross_val_score and the rest of your code stays put. It also handles the harder cousins of this problem, like combinatorial splits that give you several backtest paths instead of one. The documentation has runnable examples if you want to try it on your own data.
The takeaway
If your data has a clock attached to it, treat a high cross-validation score with suspicion until you know the split respects that clock. Purging is not there to make your numbers look better. It is there to stop them looking better than they are. A model that survives an honest split is one you can actually trust outside your notebook.
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
