

Hello dear reader! Hope you’re doing well. In this article we will provide a brief introduction to Pandas, one of the most famous Python libraries for Data Science and Machine learning. It will help you understand its fundamentals, what it is, and how to get started.
Lets get to it!
Introduction to Pandas – The fundamentals

Pandas is a popular and powerful open-source data analysis and manipulation library for the Python programming language. It is used by us, almighty data scientists and analysts to work with large datasets, perform complex operations, and create powerful data visualizations.
Most of the times when we train or build a Machine learning model, the input that we provide to it for the training is a Pandas Dataframe.
The name “Pandas” is derived from the term “panel data”, which refers to multi-dimensional data sets that are commonly used in econometrics. The library is built on top of the popular numerical computing library NumPy and provides high-performance data structures and functions for working with structured and unstructured data.
No products found.
The previous book is a great one to get started with the library, as the author is the lovely Wes McKinney, one of the creators of Pandas, so if you want to get your knowledge from 0 to hero, you should definitely consider checking it out.
In any case, to get started go over to the following page: Pandas set up tutorial, where you will find the official documentation to get Pandas up and running.
Introduction to Pandas – Key Features
Alright, now that we have seen what Pandas is, lets see some of its key features:
- A powerful data manipulation engine that allows you to easily manipulate large datasets
- Tools for reading and writing data to a variety of formats, including CSV, Excel, and SQL databases
- A rich set of functions for performing statistical analysis and data visualization
- Integration with other popular Python libraries for scientific computing, such as scikit-learn for machine learning and matplotlib for plotting and visualization
- Support for working with missing or incomplete data, and tools for handling time series data.
This last one is one of the key features of Pandas: its ability to handle missing data gracefully. This is important because real-world datasets are often incomplete or contain errors, and Pandas provides a number of tools and functions for handling missing values and dealing with them in a way that is easy and intuitive but at the same time versatile and powerful.
Lets see an example of a Pandas Dataframe, one of the most important building blocks on the library. On further posts we will explain these data objects in details, but for now just think of them as tables:
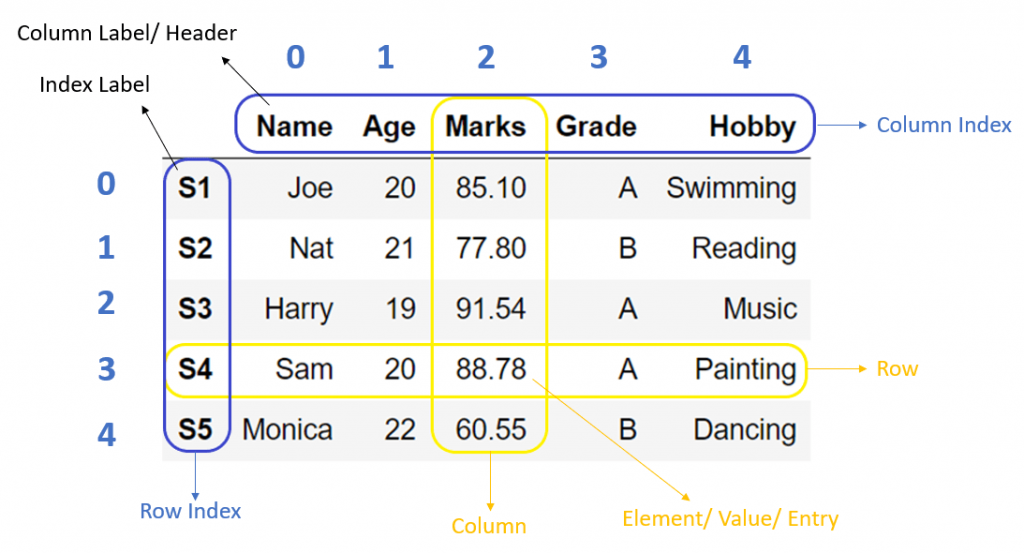
As you can see, if has a very similar structure to an Excel table (sorry for mentioning the Voldemort of Data Science), but it has many many features that make them way more awesome than excel, as we will see in the future.
Summary
Pandas is a versatile and powerful tool that can help you with a wide range of data analysis and visualization tasks. As a Data scientist, it will be one of your most used day-today tools, so you better understand it from top to bottom. We hope this quick introduction has made you understand a little bit what pandas is all about.
See you in the next pandas tutorial!
As always thank you for reading How to Learn Machine Learning and keep on learning! Also, for books that provide an introduction to Pandas like, check out our Data Analysis books section!
Subscribe to our awesome newsletter to get the best content on your journey to learn Machine Learning, including some exclusive free goodies!
